
Apache Hadoop est un framework open-source pour stocker et traiter les données volumineuses sur un cluster. Il est utilisé par un grand nombre de contributeurs et utilisateurs. Il a une licence Apache 2.0. Pour l’utiliser sur un exemple, on doit passer par certaines étapes qu’on va détailler dans cet article.
Étape 1 : téléchargement
Pour installer hadoop sur une machine qui utilise windows 10, 8 ou 7 comme système d’exploitation, on a besoin de télécharger certaines fichiers:
- Hadoop: hadoop-***.tar.gz: https://hadoop.apache.org/releases.html
- La configuration Hadoop, Configuration.zip: https://drive.google.com/file/d/1AMqV4F5ybPF4ab4CeK8B3AsjdGtQCdvy/view
- Java JDK (version >=1.8) et on l’installe (par exemple) sous “
C:\Java“: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Étape 2 : configuration
Après avoir télécharger Hadoop, on l’extrait sous “C:\“, et on configure les variables d’environnement pour Hadoop et pour Java.
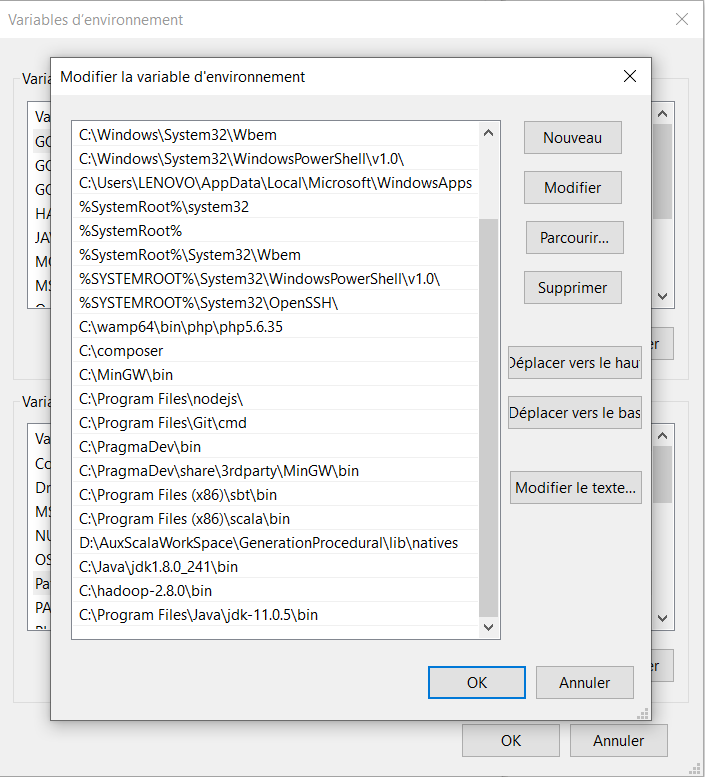
Pour accéder aux variables d’environnement, il suffit juste de taper dans la zone de recherche de programmes sur Windows X Modifier les variables, et choisir la première option.
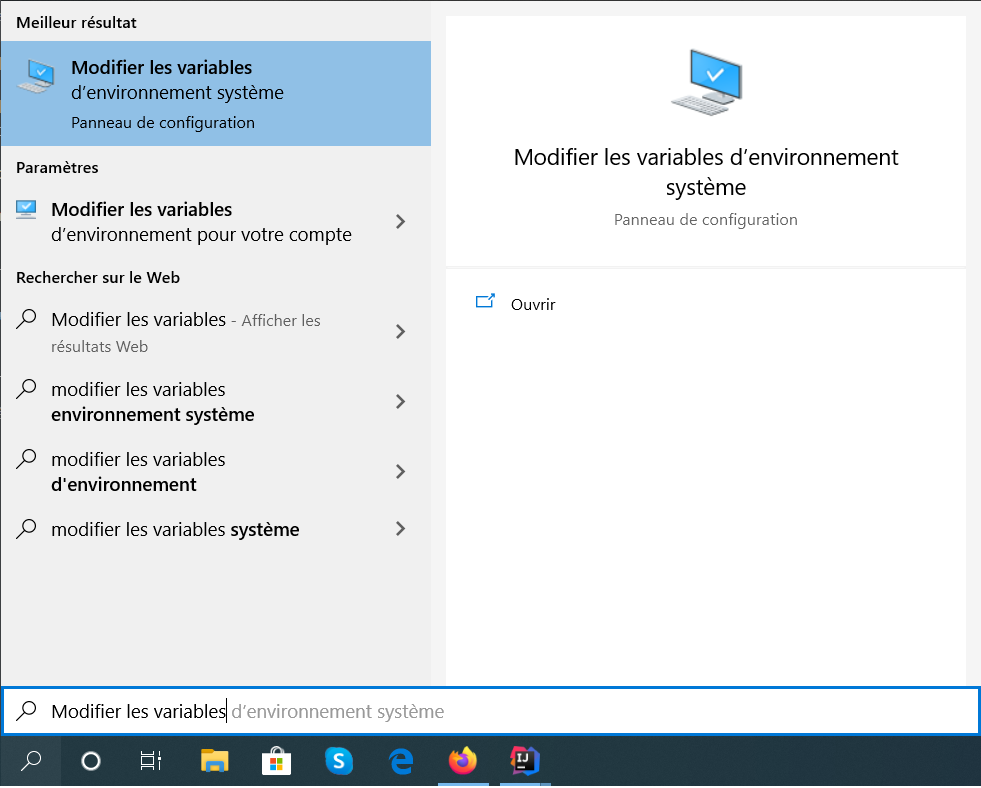
Ensuite, il faut choisir l’option Variables d’environnement.
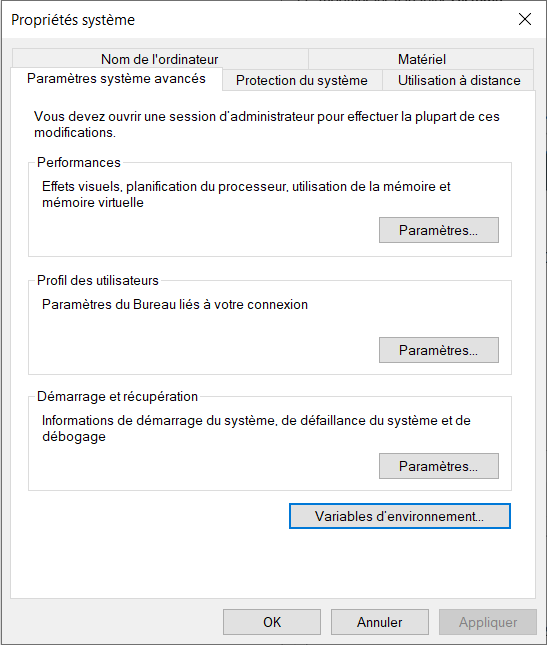
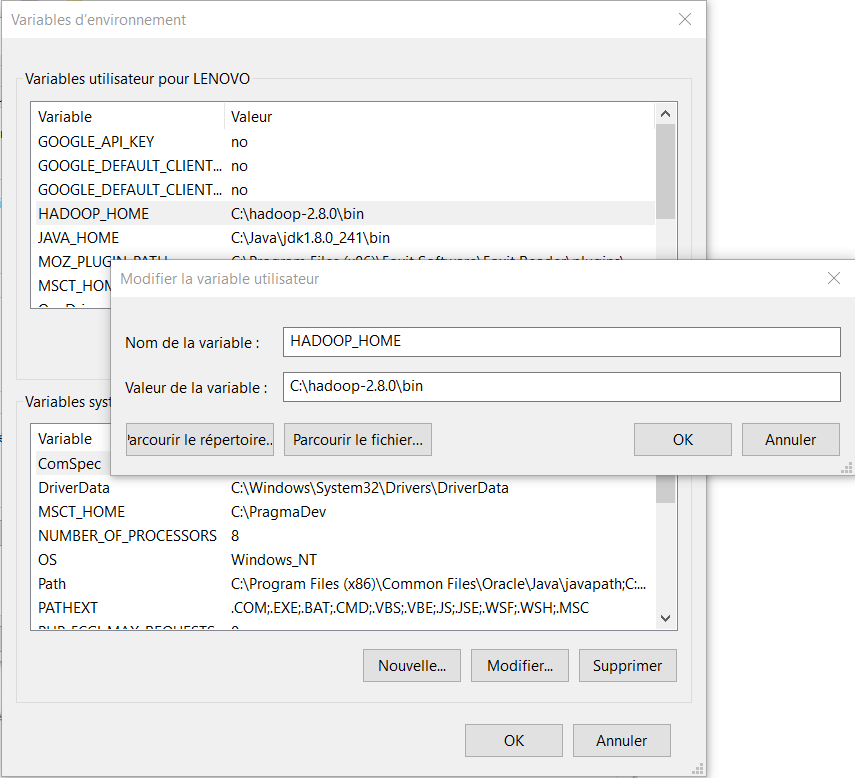
Maintenant, on peut commencer à la configuration de variables d’environnement pour Hadoop et Java.
- Hadoop
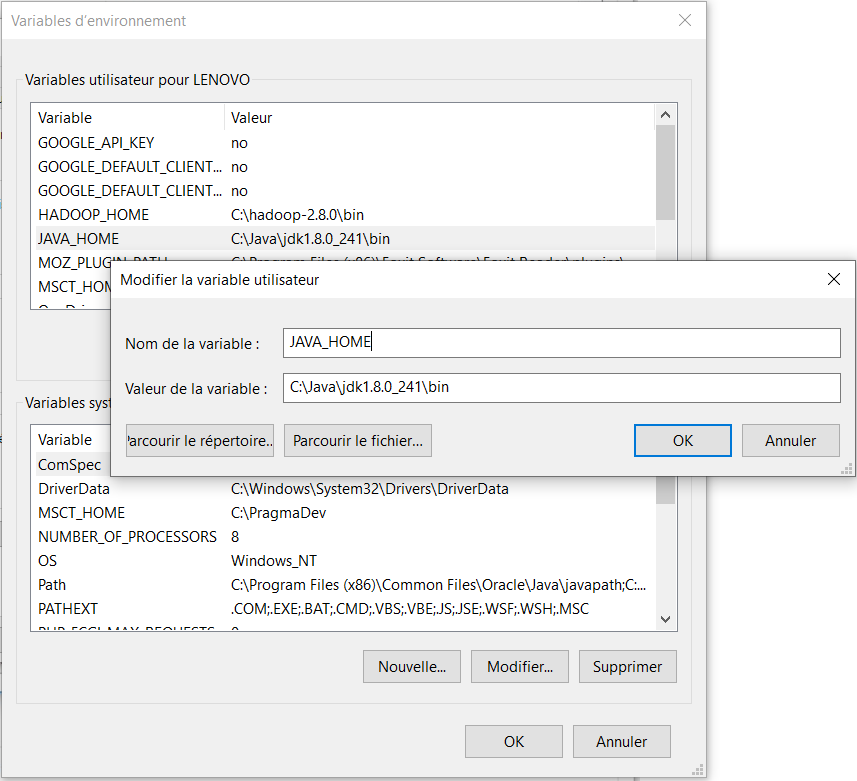
- Java
Étape 3 : Configuration
Il faut tout d’abord configurer Hadoop en mode nœud unique en éditant le fichier etc/hadoop/core-site.xml de la manière suivante:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
On a spécifié ici le nom du système de fichier. Tous les répertoires et fichiers HDFS seront donc préfixés par hdfs://localhost:9000.
Il faut ensuite configurer les paramètres spécifiques à MapReduce qui sont dans le fichier etc/hadoop/mapred-site.xml.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Ici nous avons précisé que nous allons utiliser YARN comme implémentation de MapReduce.
Maintenant, on crée un dossier data sous C:/hadoop-***, et sous ce dernier, on crée deux dossiers datanode et namenode.

Le fichier etc/hadoop/hdfs-site.xml contient les paramètres spécifiques au système de fichiers HDFS. Nous l’éditons de la manière suivante:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>C:\hadoop-2.8.0\data\namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>C:\hadoop-2.8.0\data\datanode</value> </property> </configuration>
On doit aussi paramétrer YARN via le fichier etc/hadoop/yarn-site.xml.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Nous pouvons aussi configurer les paramètres l’emplacement de Java dans le fichier etc/hadoop/hadoop-env.cmd.
@rem The java implementation to use. Required. @rem set JAVA_HOME=%JAVA_HOME% set JAVA_HOME=C:\Java\jdk1.8.0_241 @rem The jsvc implementation to use. Jsvc is required to run secure datanodes. @rem set JSVC_HOME=%JSVC_HOME%
Enfin, on dézippe le fichier Configuration.zip que on a téléchargé, et on remplace le dossier bin sous C:/hadoop-*** par celui au niveau de dossier Configuration.
Étape 4 : Exécution
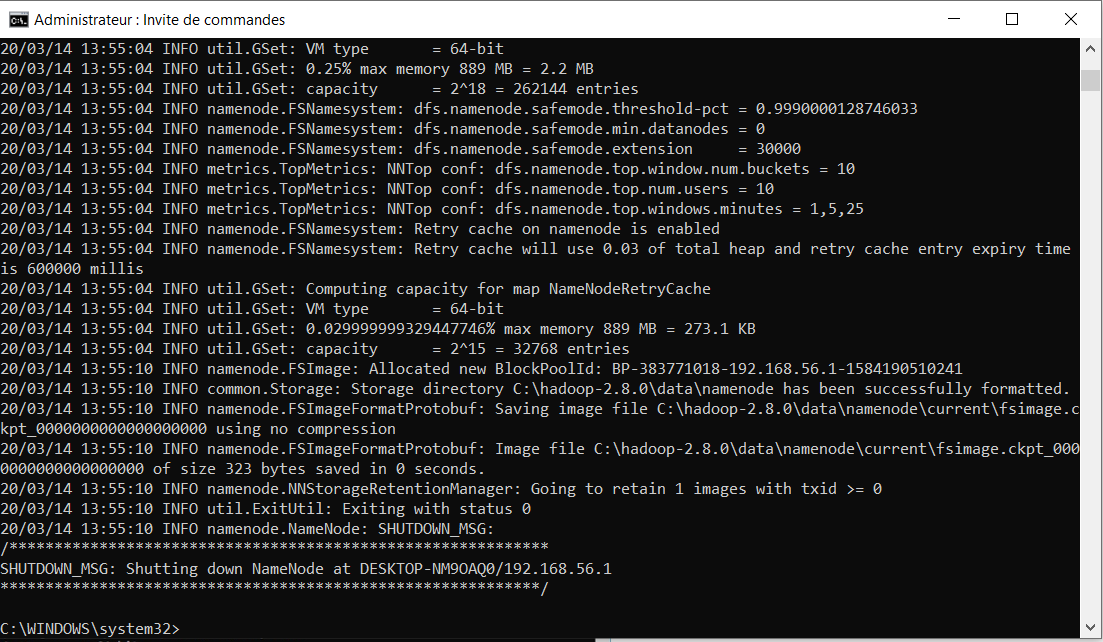
Tout d’abord, on ouvre une invite de commande en mode administrateur et on tape la commande suivante hdfs namenode –format, qui permet de formater le système de fichiers HDFS local.
Enfin, on peut taper démarrer hadoop en tapant la commande start-all.cmd à partir de C:\hadoop-***\sbin
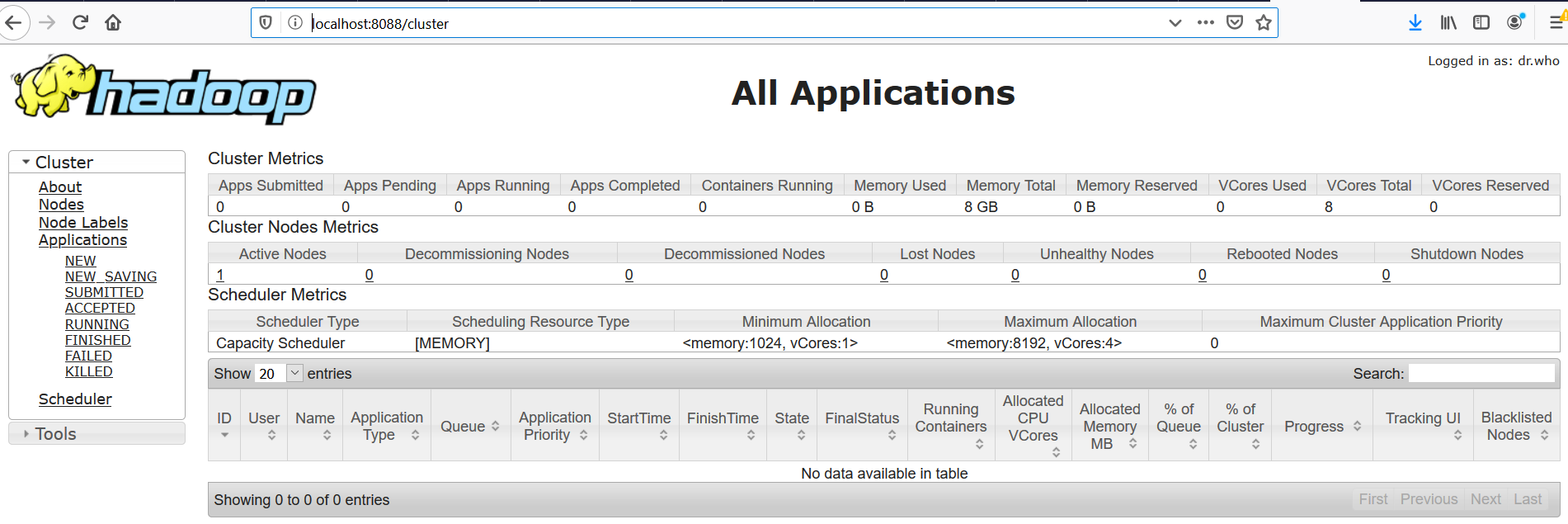
Hadoop offre plusieurs interfaces web pour pouvoir observer le comportement de ses différentes composantes. Le port 8088 permet d’afficher les informations du resource manager de Yarn et visualiser le comportement des différents jobs(avancement et résultat) en allant à l’adresse http://localhost:8088/cluster, comme il montre la figure ci-dessous.
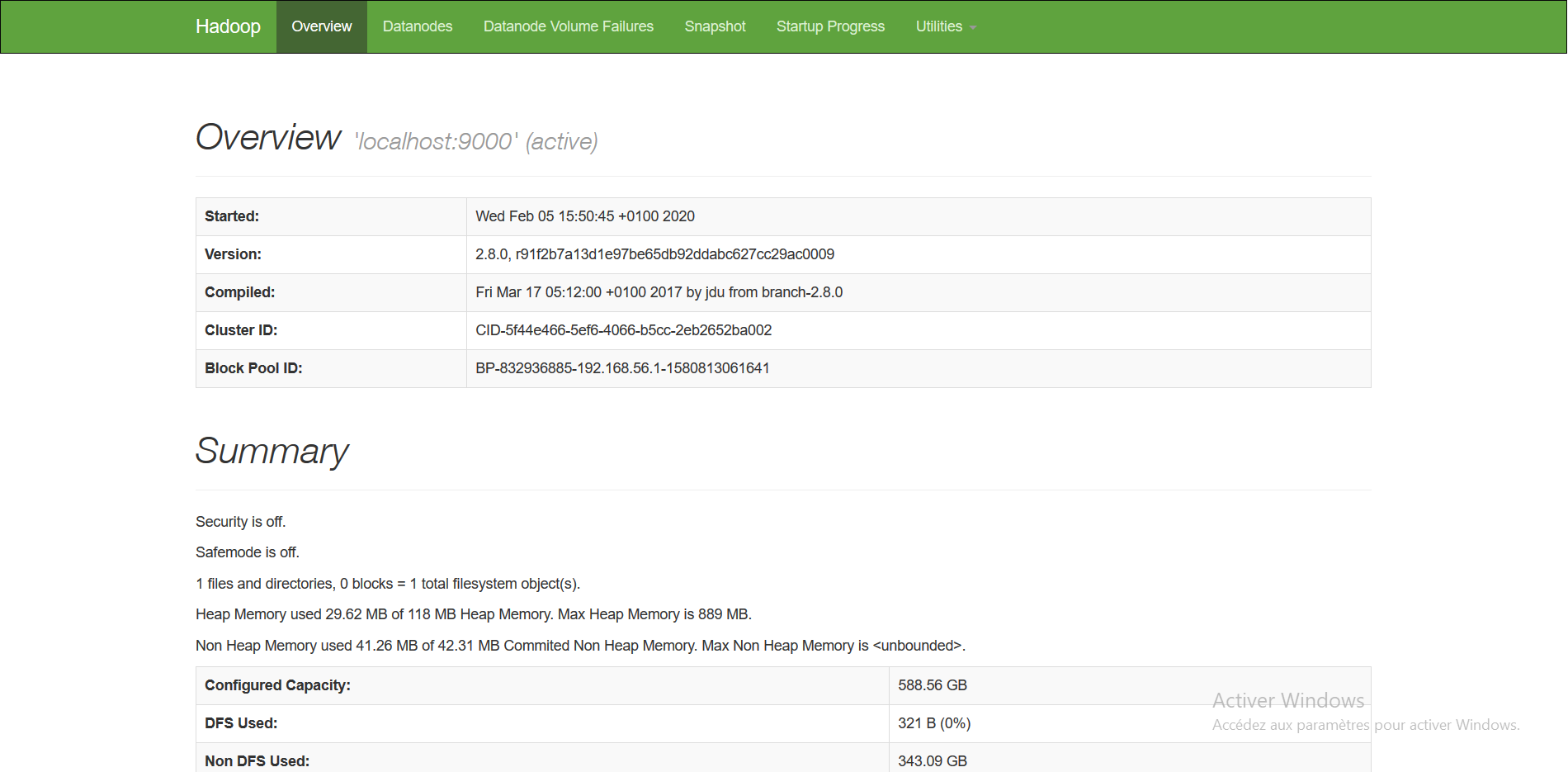
Le port 50070 qui permet d’afficher les informations de votre namenode en consultant l’adresse http://localhost:50070, comme il montre la figure ci-dessous.
Étape 5 : Un exemple, WordCount
WordCount est un exemple très simple, l’équivalent du HelloWorld pour les applications de traitement de données. Le Wordcount permet de calculer le nombre de mots dans un fichier donné, en décomposant le calcul en deux étapes (principe de l’algorithme map-reduce):
- L’étape de Mapping, qui permet de découper le texte en mots et de délivrer en sortie un flux textuel, où chaque ligne contient le mot trouvé, suivi de la valeur 1 (pour dire que le mot a été trouvé une fois)
- L’étape de Reducing, qui permet de faire la somme des 1 pour chaque mot, pour trouver le nombre total d’occurrences de ce mot dans le texte.
On commence par créer un projet Maven dans IntelliJ IDEA ou Eclipse IDEA, en définissant les valeurs suivantes pour le projet:
GroupId: hadoop.mapreduceArtifactId: wordcountVersion: 1
Ensuite, on ouvre le fichier pom.xml, et on ajoute les dépendances suivantes pour Hadoop, HDFS et Map Reduce:
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8.0_241</version>
<scope>system</scope>
<systemPath>C:/Java/jdk1.8.0_241/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.8.0</version>
</dependency>
</dependencies>
On crée la classe TokenizerMapper sous le package hadoop.mapreduce.wordcount contenant le code suivant:
package hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper.Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
La classe TokenizerMapper implémente la classe org.apache.hadoop.mapreduce.Mapper de Hadoop que l’on paramètre avec le type de la clé d’entrée (Object), le type de la valeur d’entrée (Text), le type de la clé des sorties intermédiaires (Text) et enfin le type de la valeur des sorties intermédiaires ( IntWritable). On remarque pour écrire un programme MapReduce, on ne peut pas utiliser les types standard de Java. Il faut utiliser des types spéciaux qui vont permettre la transmission efficace des données entre les différentes machines du cluster car on a besoin de l’aspect sérialisation et désérialisation des données. Pour écrire le code correspondant à l’opération Map, nous avons utilisons ici les types InitWritable et Text. La fonction map retourne le texte découpé en un ensemble de lignes où chacun entre eux sera stocker au niveau de la variable word suivi de la valeur 1.
Maintenant, On crée la classe IntSumReducer sous le package hadoop.mapreduce.wordcount contenant le code suivant:
package hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
System.out.println("value: "+val.get());
sum += val.get();
}
System.out.println("--> Sum = "+sum);
result.set(sum);
context.write(key, result);
}
}
La classe IntSumReducer implémente la classe org.apache.hadoop.mapreduce.Reducer de Hadoop que l’on paramètre avec le type de la clé d’entrée (Text), le type de la valeur d’entrée ( IntWritable ), le type de la clé des sorties intermédiaires (Text) et enfin le type de la valeur des sorties intermédiaires ( IntWritable). Pour écrire le code correspondant à l’opération reduce , nous avons utilisons ici les types InitWritable et Text. La fonction reduce commence à parcourir la liste values qui est le résultat de la fonction map et elle compte le nombre d’occurrence de chaque mot dans le texte. A la fin, elle retourne le mot et son nombre d’occurrence.
Enfin, on crée la classe WordCount sous le package hadoop.mapreduce.wordcount contenant le code suivant:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
//Récupérer la configuration générale du cluster
Configuration conf = new Configuration();
//Créer un job
Job job = Job.getInstance(conf, "word count");
//Préciser quelles sont les classes Map et Reduce du programme
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
//Préciser les types de clés et de valeur correspondant à notre problème
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//Indiquer où sont les données d'entrée et de sortie dans HDFS
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Lancer l'exécution de la tâche
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
La classe WordCount qui contient la fonction main du programme et qui va permettre de :
- Récupérer la configuration générale du cluster.
- Créer un job.
- Préciser quelles sont les classes Map et Reduce du programme.
- Préciser les types de clés et de valeur correspondant à notre problème
- Indiquer où sont les données d’entrée et de sortie dans HDFS.
- Lancer l’exécution de la tâche.
Tester Map Reduce en local
Dans le projet sur IntelliJ:
- On crée un répertoire input sous le répertoire resources de projet
- On génère 1000 mots avec de duplications en se servant de ce site https://www.randomlists.com/random-words.
- On crée un fichier de test: file.txt dans lequel on insère les 1000 mots
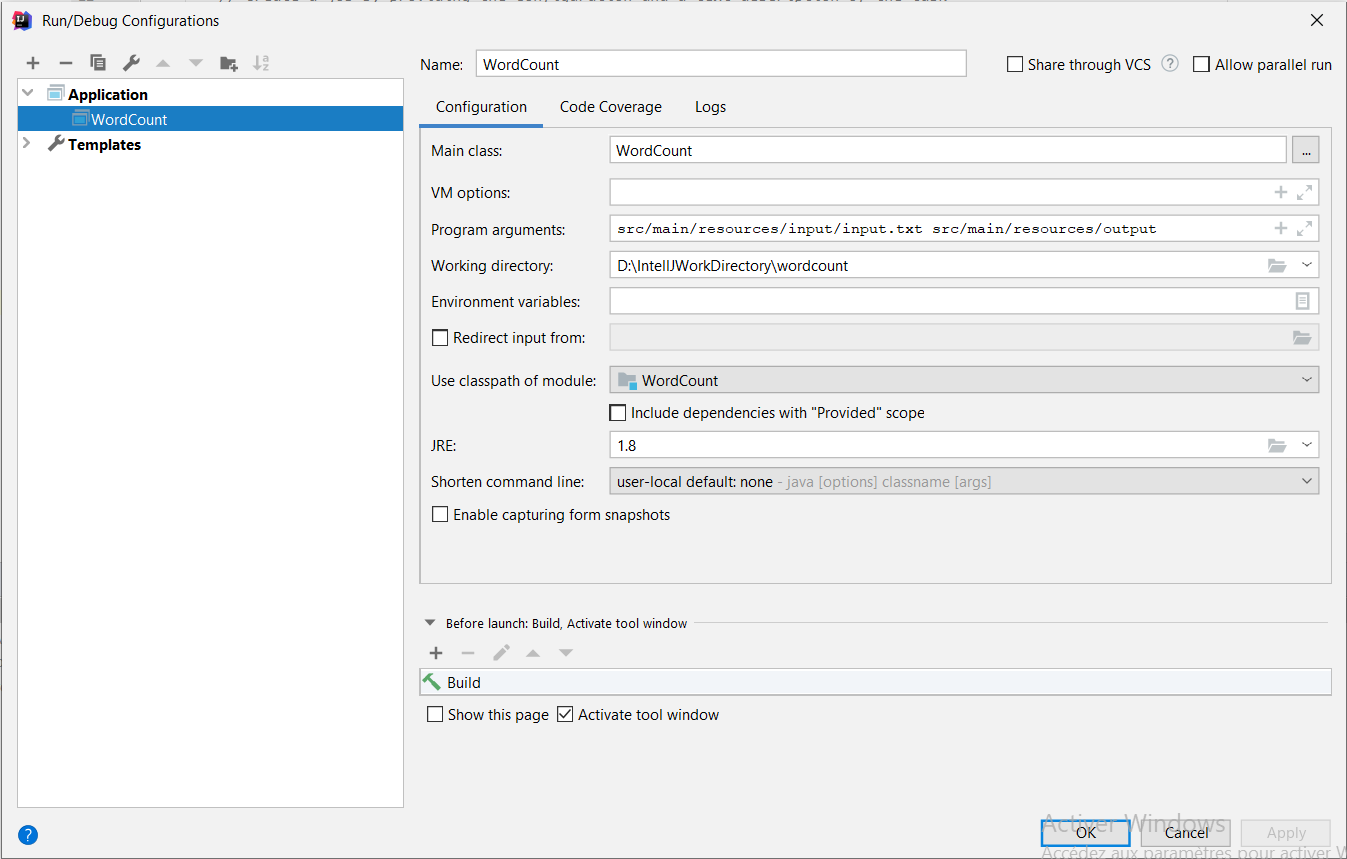
- On crée une configuration de type Application (Run->Edit Configurations…->+->Application).
- On définir comme Main Class: hadoop.mapreduce.wordcount.WordCount, et comme Program Arguments: src/main/resources/input/file.txt src/main/resources/output
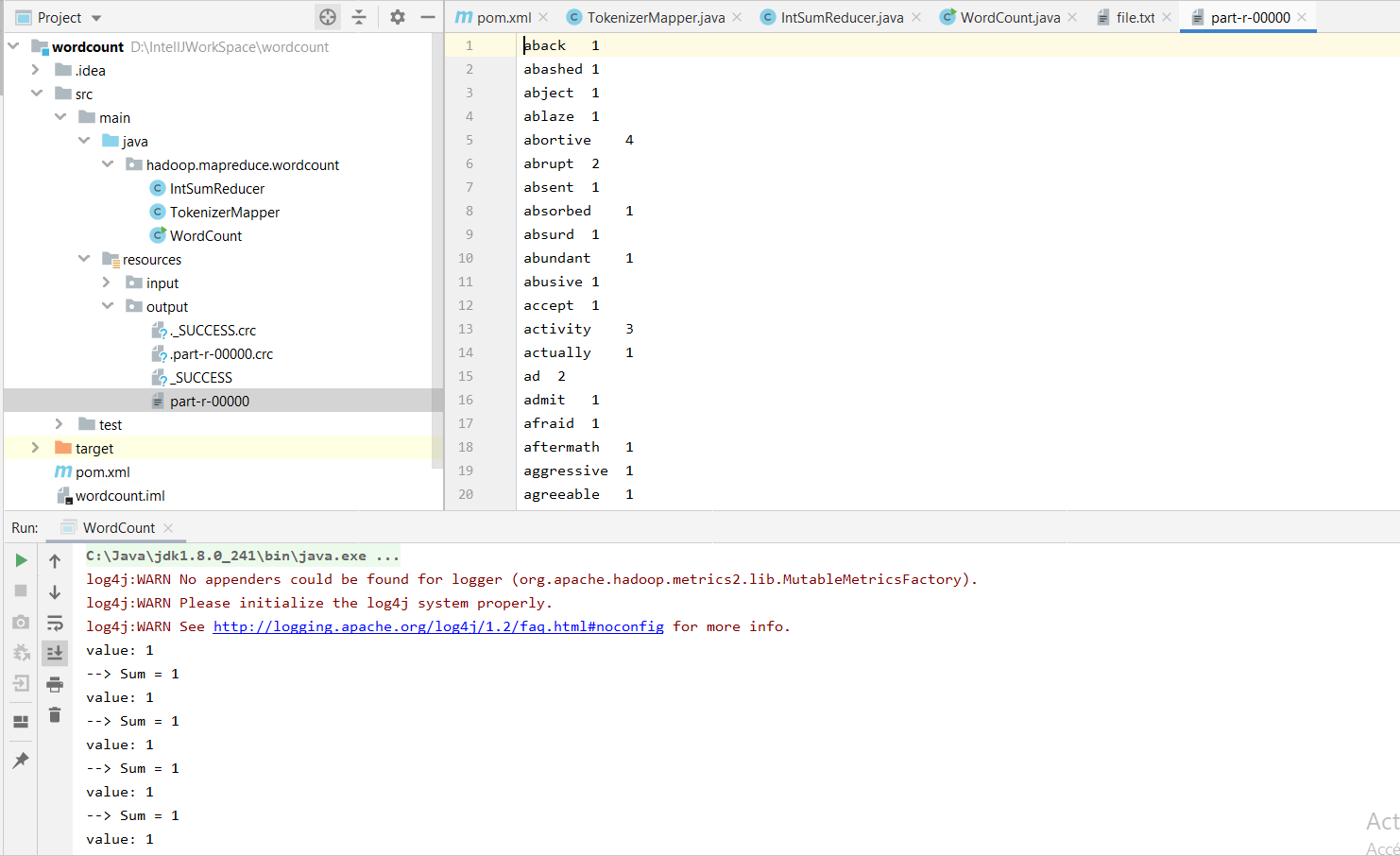
- On lance le programme. Un répertoire output sera créé dans le répertoire resources, contenant notamment un fichier part-r-00000, dont le contenu devrait être le suivant:
Pour plus de détails sur le paradigme de programmation MapReduce: https://static.googleusercontent.com/media/research.google.com/fr//archive/mapreduce-osdi04.pdf
Lien pour tester le programme wordcount: https://gitlab.com/soufienjabeur/wordcount

Ping : WordCount Multi-Input sous Hadoop – Sysblog
Hello,
Super tuto merci pour les infos.
Par contre fais attention, ton tuto est quand même truffé de petites erreurs 🙂