
Au cours de la durée d’utilisation d’un ordinateur, une énorme quantité d’instructions machine est exécutée par ce qu’on appelle un processeur (unité centrale de traitement, UCT en anglais). Ce composant indispensable est présent dans tous les ordinateurs et joue un rôle fondamental dans le son fonctionnement. Cependant, les capacités du processeur ne sont pas infinies, ce qui implique une bonne gestion de toutes ces requêtes. C’est ce que nous allons voir dans la suite de cet article.
Processeur, processus
Le processeur est la pièce maîtresse d’un ordinateur, c’est à lui qui convient de faire le lien entre les différents composants (RAM, disque dur etc..) et tout le travail en arrière-plan. Il peut traiter des milliards d’informations chaque seconde, c’est de là que provient toute la puissance des ordinateurs.
Les programmes informatiques sont, à la chaîne, exécutés par le processeur. On appelle « processus » une instance d’un de ces programmes qui est en train d’être exécutée sur un ou plusieurs processeurs.
Tout processus possède un début, une fin et peut être dans divers états intermédiaires dont « actif » et « attente ».
Ci-dessous, voici une partie de la structure qui représente un processus dans le noyau (on reviendra sur certains attributs un peu plus loin) :
struct task_struct {
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
…
unsigned int policy;
…
};
Temps réel
On ne va pas s’attarder en détails sur la notion de temps réel et tout ce qu’elle comporte, cependant nous allons jeter un petit coup d’œil sur ce que cela implique plus ou moins au niveau des processus.
Il existe différentes sortes de processus : « en temps réel » et ceux dits « normaux »
La grande différences entre les deux étant que les processus en temps réel ont une certaines garantie que leur exécution sera effectuée dans des limites de temps (plus ou moins strictes).
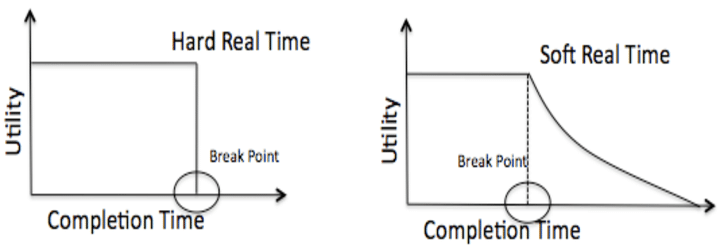
Il existe en existe deux types :
- Soft : Ils possèdent des bornes d’exécution. Pour autant, même si par hasard leur exécution dépasse le temps imparti, ce n’est pas dramatique et l’utilisateur ne risque pas grand-chose (décalage –lag– vidéo).
- Hard : Ils sont limités par des délais stricts. Cependant les tâches ne doivent jamais se terminer après la limite fixée même dans la pire des situations d’exécution possible. En gros ne pas donner de résultat est bien pire que d’en donner un incomplet.
Exemples : pilote automatique d’avion, système de surveillance de centrale nucléaire. Le problème est évidemment bien plus compliqué à gérer.
Scheduling
Le scheduling (ordonnancement en français) est un mécanisme permettant à un processeur de gérer le flux de processus. En effet, malgré nos précédents dires sur la puissance du processeur, il n’est pas possible d’exécuter en même temps chaque instance de programmes. Donc il faut pouvoir exécuter certaines tâches à un certain moment et certaines tâches à d’autres.
Évidemment dans un système aussi complexe, le choix ne peut être aléatoire sous peine d’une mauvaise optimisation des ressources et des besoins de l’utilisateur.
Priorité d’un processus
Pour faire se faire, il faut donc des critères pour sélectionner un processus plutôt qu’un autre. De manière traditionnelle, on utilise l’une des priorités d’un processus : « nice value ».
Chaque processus s’exécute avec une priorité. Cette valeur varie de -20 à +20. La priorité maximale est -20 et la minimal +20. Par défaut les processus s’exécutent avec une priorité de 0.
Il existe des commandes pour contrôler la priorité des processus : nice, renice.
nice -n increment_priority utility renice -n priority -p PID
À vrai dire, cette propriété s’applique aux processus « normaux ». Pour les processus en temps réel, on utilise la propriété real_time_priority, la plage de valeurs va de 1 à 99. Cependant, ici plus la propriété est élevée et plus le processus est prioritaire.
N’importe quel processus en temps réel est bien plus prioritaire que tous les processus normaux

Les algorithmes
Il n’existe pas une unique manière d’ordonnancer dans le noyau (kernel) Linux. En effet les processus normaux et en temps réel sont gérés de manière distincte. La façon dont va être gérer un processus est définie avec l’attribut « policy ». Il en existe trois types : SCHED_OTHER pour les processus normaux et SCHED_FIFO, SCHED_RR ceux en temps réel.
Les algorithmes normaux
Dans les premières versions de Linux, l’algorithme de scheduling était assez simple et direct : le noyau analysait la liste des processus en attente, calculait leur priorité et sélectionnait le meilleur candidat. C’est simple et efficace, cependant l’inconvénient était que le temps passé à choisir dépendait du nombre de processus exécutables. Ainsi, avec un énorme nombre de processus, l’algorithme devenait un peu trop coûteux en temps. Dans le passé cela posait moins de problème étant donné que le nombre de processus était assez limité mais de nos jours ça ne l’est plus.
void schedule(void) {
int i,next,c;
struct task_struct ** p;
/* check alarm, wake up any interruptible tasks
that have got a signal */
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) {
if ((*p)->alarm && (*p)->alarm < jiffies) {
(*p)->signal |= (1<<(SIGALRM-1));
(*p)->alarm = 0;
}
if ((*p)->signal && (*p)->state==TASK_INTERRUPTIBLE)
(*p)->state=TASK_RUNNING;
}
/* this is the scheduler proper: */
while (1) {
c = -1;
next = 0;
i = NR_TASKS;
p = &task[NR_TASKS];
while (--i) {
if (!*--p)
continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
if (c) break;
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p)
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
switch_to(next);
}
Linux 0.01 process scheduler
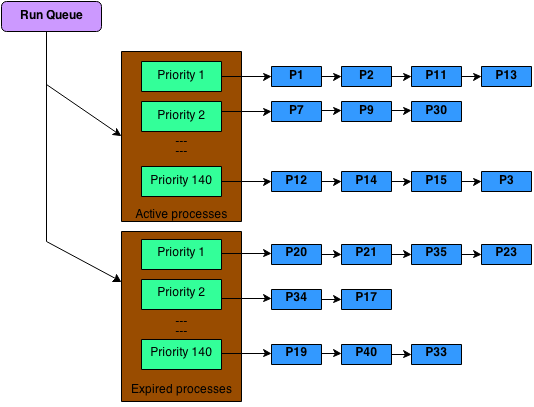
En 2003, avec la nouvelle version 2.6 de Linux, une nouvelle version est apparue nommée « O(1) scheduler ». Ce nouvel algorithme se veut plus performant et sophistiqué. Il s’appuie sur l’utilisation de deux tableaux pour chaque priorité. On a vu précédemment qu’il y a 140 priorités, cela fait donc 280 tableaux. Deux tableaux pour stocker les processus actifs alors que le second gère les processus expirés. Lorsqu’un processus a fini d’utiliser sa tranche de temps, il est déplacé vers les processus expirés. Une fois que tous les tranches de temps des processus actifs sont terminées, on échange, la file d’attente des expirés devient active.
Avec ce procédé, au lieu de tourner en O(n) comme l’ancien algorithme, on est en O(1), d’où le nom de ce scheduler.
Finalement en 2007, le Completely Fair Scheduler (CFS) a été introduit. Il est depuis l’algorithme par défault de planification de linux.
L’auteur de cet algorithme, Info Monlnar, a dit:
CFS basically models an ‘ideal, precise multitasking CPU’ on real hardware.
Essayons d’analysez et comprendre ce que cela veut dire.
Un CPU idéal, précis et multitâche et un processeur qui peut exécuter plusieurs tâches parallèlement en donnant la même puissance à chaque processus. Par exemple, s’il y a 2 processus, chacun percevra 50% de puissance simultanément. Pour 5, 20% etc..
Un tel processeur n’existe pas, cependant le CFS essaie de simuler cette planification équitable.
L’idée principale derrière le CFS est de maintenir une équité en donnant du temps à tous les processus. Lorsqu’il y a un déséquilibre, les tâches en questions doivent alors recevoir du temps. C’est à dire que la tâche avec le plus grand temps d’attente est sélectionnée et exécutée par le processeur. Pendant ce temps, le temps d’attente d’un autre processus va augmenter, et par conséquent il y aura un nouveau processus avec un temps d’attente le plus élevé.
Cette fois-ci, le planificateur n’utilise pas de files d’attentes, mais il maintient un red-balck tree.
Il s’agit d’une variante d’arbre binaire qui possèdent des propriétés intéressantes. Il est équilibré, ce qui évite d’avoir certains chemins d’accès d’une longueur disproportionnée. Deuxièmement, les opérations sur l’arbre sont en O(log n).
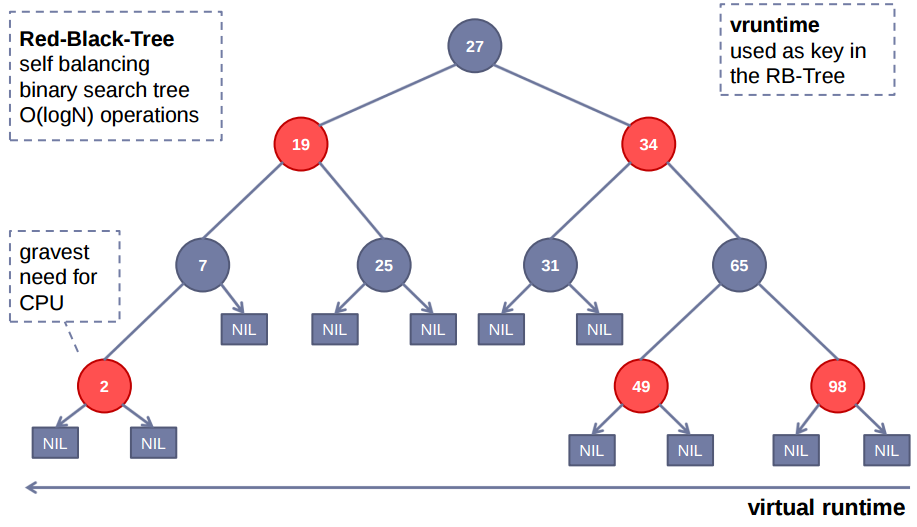
La tâche qui a le plus besoin de CPU est placée tout à gauche. Le CFS sélectionne cette tâche et au fur et à mesure, les tâches qui ont été exécutées sont placées à droite. Cela permet de donner une chance à tous les processus.
Contrairement aux précédents algorithmes, CFS n’utilise pas directement les priorités, mais il les utilise plutôt comme un facteur de décroissance du temps d’exécution. Plus les priorités sont faibles, plus le temps d’exécution se dissipe rapidement.
Les algorithmes en temps réel
On a vu précédemment que lorsqu’une tache en temps réel existe, elle sera exécutée avant toute autre tâche normale. Cependant, lorsqu’elles sont plusieurs, deux types de « policy » existent :
SCHED_FIFO: Il s’agit d’une implémentation First_In_First_Out. Lorsqu’un processus est sélectionné pour s’exécuter, il continuera jusqu’à ce que son exécution termine ou alors s’il est préempté par un processus avec une meilleur priorité.SCHED_RR: L’implémentation Round Robin est identique àSCHED_FIFO, cependant les processus ne peuvent s’exécuter que pendant un laps de temps maximum. Après cela, le processus est déplacé dans la file d’attente et un autre processus est sélectionné.
La planification des processus est une préoccupation majeure des systèmes d’exploitation, et on peut être sûr qu’elle continuera de l’être dans le futur.
Aujourd’hui nous avons un planificateur assez efficace et équitable. Cependant nous avons vu que les algorithmes ne cessent d’évoluer, nul doute qu’il en sera de même pour le CFS.
