Dans cet article nous allons présenter le principe de containérisation; qu’est-ce qu’un container et quelle est son utilité ? Nous seront alors amené à étudier deux fonctionnalités importantes du noyau Linux : les cgroups et les namespace.
Qu’est-ce que la containérisation ?
La containérisation est une technique qui permet d’empaqueter votre application et toutes ses dépendances ensemble sous la forme d’un container pour assurer que votre application fonctionne de manière identique dans tout les environnements.
Docker : plateforme de containérisation
Docker est une plateforme de containérisation créer pour les développeurs pour leurs permettre d’écrire du code sans se soucier de l’environnement dans lequel auront lieu les tests/ la production; Mais aussi pour les administrateurs systèmes qui n’ont plus à se soucier de l’infrastructure car Docker met à l’échelle facilement le nombre de systèmes utilisées, et permet de gérer facilement les containers contenant les applications (pour pouvoir les déplacer en cas de pannes par exemple).
Vous pouvez trouver ici un tutoriel pour découvrir les bases de Docker en 7 étapes.
Il existe également d’autres plateforme de containérisation comme LXC Linux Containers, Mesos Containerizer, OpenVZ … (que nous ne verrons pas ici).
Qu’est ce qu’un container ?
Un container est lancé en exécutant une image: une image est un paquet exécutable qui inclus tout ce dont à besoin l’application pour s’exécuter (le code, l’environnement d’exécution, les librairies, les variables d’environnement, les fichiers de configuration).
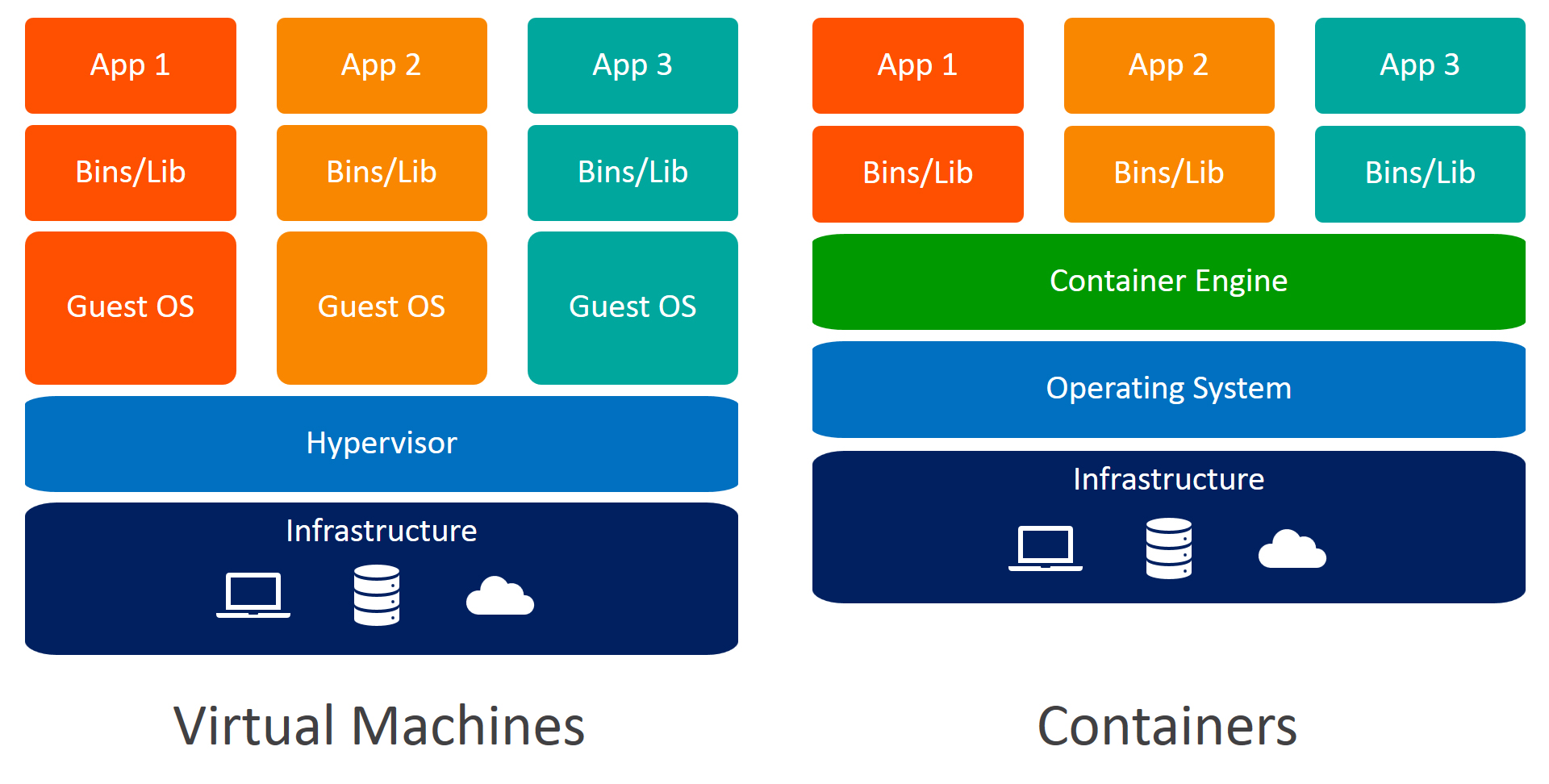
Un container est donc une instance d’exécution d’une image qui s’exécute nativement sur Linux et qui partage le noyau de la machine hôte avec les autres containers. Il lance alors un processus qui ne prend pas plus de mémoire qu’un autre exécutable, le rendant plus léger en comparaison aux machines virtuelles.
Pour créer un container avec Docker, on utilise un Dockerfile pour définir ce qui se passe dans l’environnement à l’intérieur du container.
Containérisation VS Virtualisation
La containérisation est juste de la virtualisation au niveau du système d’exploitation, le rendant plus efficace car il n’y a pas de système d’exploitation hôte, contrairement à la virtualisation qui maintient plusieurs OS sur la même machine, et utilisant un hypervisor pour communiquer avec le système d’exploitation hôte.
Tout les containers sont basés sur le même environnement: ils ont donc tous accès au même CPU. Ils partagent le noyau de l’OS les rendant plus léger et plus petit. La containérisation offre donc une meilleure utilisation des ressources comparé aux machines virtuelles.
Les namespaces & cgroups
Docker utilise des fonctionnalités du noyau Linux pour assurer l’isolation des containers, telles que les cgroups, les namespaces ainsi qu’un système de fichier tel que UnionFS/OverlayFS. Cela permet d’exécuter des containers indépendamment avec une seul instance de Linux. Ils permettent d’assurer une certaine isolation des ressources, et donc une certaine sécurité : pour en savoir plus, allez voir cet article sur la sécurité et Docker.
Les namespaces
Les namespaces permettent d’isoler le point de vue d’une application de l’environnement : process trees network, les systèmes de fichiers et les user’s ID. Autrement dit, les namespaces permettent de limiter ce que peut voir l’application, ou plus généralement ils permettent de séparer les ressources du noyau tel qu’un ensemble de processus voit un ensemble de ressources tandis qu’un autre ensemble de processus verra un ensemble de ressources différent.
Différents namespaces
Il existe de multiple namespaces (pid, net, mnt, uts, ipc, user) qui permettent de créer plusieurs groupes d’isolation. Chaque processus appartient à un namespace de chaque type, et les namespaces peuvent être imbriqués les un dans les autres.
Ils sont matérialisés par des pseudo-files lister dans /proc/<pid>/ns, ce qui nous permet, pour un <pid> donné, de lister ses namespaces par la commande ls /proc/<pid>/ns -ail.
Il est aussi possible de lister les namespaces de chaque processus avec la commande lsns -l, dont les namespace apparaissent dans la colonne NS et dont le type (user, pid …) est renseigné dans le champs TYPE. Pour lister tout les processus appartenant à un type de namespace donné, il suffit de le spécifier dans la commande, par exemple si je veux lister tout les namespaces de type user, je peux utiliser la commande lsns -t user, et en règle générale utiliser la commande lsns -t <type>, où <type>doit être mnt, net, ipc, user, pid, uts ou cgroup. Il est donc aussi possible de lister les cgroups par la commande lsns -t cgroup.
Un namespace est créer avec l’appel système clone(), en ajoutant des flags quand on crée un nouveau processus. Il est aussi possible de créer un namespace par la commande setns(). Quand le dernier processus d’un namespace se termine, le namespace est détruit. Chaque processus appartient à un namespace de chaque type.
Voyons les principaux namespaces et leurs utilités:
- Pid Namespace: permet d’isoler l’ ID number space, impliquant que des processus dans différents PID namespaces peuvent avoir le même PID. Chaque processus a son propre identifiant, commençant à 1. Si le processus numéro 1 termine, tout le namespace est tué. Ces namespaces peuvent être imbriqué, donc une processus aura de multiple PID, un pour chaque namespace dans lequel il est imbriqué.
- User Namespace: il permet d’isoler (pour la sécurité) les identifiants et les attributs, en particulier les user ID et les group ID (voir credentials(7)), le répertoire root, les keys (voir keyrings(7)) et les capabilities (voir capabilities(7)). Les user ID et group ID d’un processus peuvent être différents à l’intérieur et à l’extérieur dans user namespace. Un processus a donc des droits différents en fonction du namespace.
- Network Namespace: chaque network namespace a sa propre network stack, iptables rules, tables de routage (routing tables), ses règles pour le pare-feu, et ses périphériques réseaux. Il est possible de créer un network namespace grâce à la commande :
$ ip netns add ns1qui crée un nouveau namespace nomméns1. Il est alors possible de lister les namespaces disponible dans le système avec la commande$ ls /var/run/netnsou$ ip netns. - Mount Namespace: fourni une isolation de la liste des points de montage (mount points) vu par les processus en fonctionne de leurs mnt namespace. Chaque processus verront donc des arborescences de répertoire propre à leurs namespaces. Il est possible d’attacher un processus à son filesystem par la commande
chrootpar exemple. - IPC Namespace: chaque IPC namespace a son propre ensemble d’identifiants System V IPC et ses propres POSIX message queue filesystem.
- UTS Namespace: permet d’isoler deux éléments du système en leurs donnant différents host et domain names (nom de domaine).
Les “Control Groups” : cgroups
Les cgroups sont une fonctionnalité du noyau Linux qui permettent de limiter, compter et isoler l’utilisation des ressources (processeur, mémoire, utilisation disques ..).
Il est donc possible de mettre en place différents cgroups pour limiter l’utilisation CPU et de la mémoire (y compris le cache du système de fichier) pour un ensemble de processus donné. Ils permettent donc la priorisation, c’est-à-dire que certains groupes peuvent obtenir une plus grande part de ressource processeur ou de bande passante d’entré/sortie, mais aussi de mesurer la quantité de ressources consommées par certains systèmes. On peut aussi figer les groupes ou créer un point de sauvegarde et redémarrer.
Pour créer un cgroup, utilisez la commande suivante : cgcreate -g subsystems:path où l’option -g spécifie la hiérarchie dans laquelle le cgroup dois être créer. Par exemple, le cgroup qui se trouve dans /cgroup/cpu/cg1, créer avec la commande cgcreate -g cpu:/cg1 s’appelle juste cg1.
L’isolation est fourni par les namespaces qui empêchent un groupe donné de processus de voir les processus des autres groupes, leurs connexions réseaux et leurs fichiers.
Nous avons donc vu à travers cet article le principe de containérisation, ce qu’est un container et à quoi cela sert, mais aussi comment les cgroups et les namespaces nous permettent d’isoler ce que peut voir chaque containers, mesurer leur utilisation des ressources et les isoler des autres containers.

