Conception d’un OS kernel
Hugo Jacotot – David Andrawos – Matthieu Le Franc
Nous tentons de présenter ici de manière non exhaustive quelques parties nécessaire à la réalisation d’un noyau de système d’exploitation. Cet article est à prendre comme un point d’entrée, une présentation de certaines composantes logicielles nécessaires à la gestion des ressources d’un ordinateur. Afin de proposer une approche originale, nous avons tenté de concevoir notre propre noyau inspiré d’UNIX pour une architecture de microprocesseurs x86 32bits. Les sections ci-dessous sont donc basées sur notre étude de cette architecture et, bien que la description générale que nous faisons du fonctionnement d’un noyau soit la plus courante, les détails techniques peuvent ne pas être compatibles avec d’autres.
Code source : https://github.com/HugoJct/HugOS/tree/master
Qu’est-ce qu’un noyau ?

Le noyau d’un système d’exploitation (kernel de l’anglais) est un programme unique permettant la communication entre le matériel et le logiciel. C’est une partie essentielle dans la plupart des systèmes car elle fournit des méthodes d’abstraction aussi bien matérielles, pour la gestion des composants physiques, que logicielles, pour les échanges d’informations entre processus ou encore l’ordonnancement des tâches.
Dans beaucoup d’implémentations un noyau permet une segmentation de la mémoire vive en deux espaces disjoints, l’un pour l’espace noyau et un autre pour l’espace utilisateur, afin de séparer la zone noyau où les actions critiques sont effectuées de la zone utilisateur où la mémoire est protégée.
Au service des processus, le noyau offre un ensemble de fonctionnalités accessibles au travers des appels système ainsi que la transmission ou la lecture du matériel par l’intermédiaire des interruptions. On nomme l’ensemble de ces actions les entrées sorties, souvent noté I/O. Le noyau du système d’exploitation forme donc un ensemble de fonctions pouvant être appelées par des processus souhaitant effectuer des actions “critiques” nécessitant un certain niveau de permissions. Le transfert de responsabilité nécessaire dans de telles situations est initié par un appel système, le noyau prend à ce moment là le relais du processus.
Appels système et Interruptions
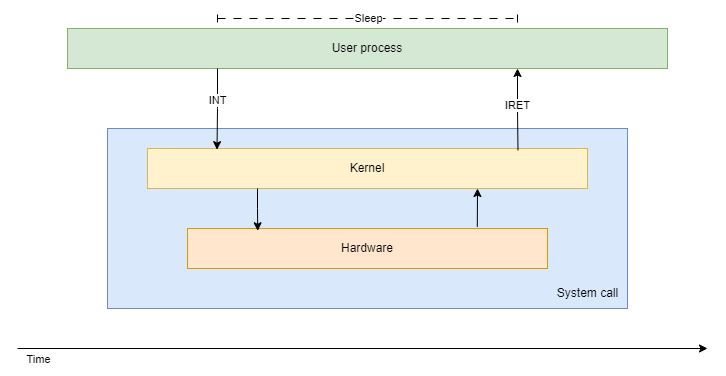
Dans tous systèmes, il est bien souvent essentiel de pouvoir permettre des interactions avec l’extérieur. Un véhicule à moteur, lancé sur la route à toute vitesse, aurait une utilité rapidement limitée s’il n’était pas possible d’utiliser un volant, un frein ou un accélérateur pour ajuster sa trajectoire. Il en va de même pour un système informatique, dont toute la durée de fonctionnement serait pleinement définie dès l’allumage, sans systèmes de navigation ou de pilotage.
Être en mesure de commander le déroulé des exécutions pendant qu’elles ont lieu, de demander l’état de certaines données ou encore de lancer ou d’interrompre un processus semble tellement évident qu’on pourrait penser, même en tant que programmeur, que les mécanismes permettant tout cela sont parfaitement naturels et innés pour n’importe quelle machine. C’est oublier que les machines binaires sont des structures XXL de stupidités dont seul l’agencement logique de chaque brique permet de proposer des fonctionnalités remarquables.
Exemples d’actions requérant des interruptions :
- Affichage sur un écran
- écriture avec les touches d’un clavier
- lecture/écriture dans la mémoire d’un disque dur
Lorsque l’on fait ce genre de demande au processeur d’une machine binaire, on ne peut pas se permettre de laisser cela dans une file d’instructions en attendant qu’il la traite. Cela reviendrait à demander à sa voiture de freiner lorsqu’elle aura fini de réaliser toutes ses tâches déjà en cours. De la même manière, sur nos ordinateurs de bureau, on ne veut pas attendre que le processeur termine l’exécution de tout un programme avant d’écouter ce qu’on a à lui dire en écrivant sur notre clavier.
Pour parvenir à demander au système de modifier son fonctionnement, beaucoup de mécanismes doivent être mis en œuvre afin de l’interrompre de manière sûre pour que son état ne soit pas perdu ou perturbé par notre action extérieure. Tout comme le serveur d’un restaurant glissant une commande au chef de cuisine sans que pour autant celui-ci mélange ses plats en préparation.
Introduction faite, rentrons un peu plus dans la technique. Nous avons parlé des interruptions matérielles, engendrée par l’action d’un périphérique, mais les plus couramment employées par un programmeur dans son travail sont les interruptions logiciels réalisés par l’intermédiaire d’appels système. Ces actions sont dites “critiques” car, mal gérées, elles peuvent amener à la corruption de données et c’est donc pourquoi les appels systèmes sont généralement implémentés par le noyau d’un système d’exploitation. À la conception d’un programme, on utilise ces fonctions et l’interface mise à disposition par le noyau pour commander les actions critiques au processeur.
Par exemple en langage C, pour commander l’écriture de données :
ssize_t write(int fd, const void *buf, size_t count); C’est donc le moment où le noyau prend le relais du programme utilisateur pour réaliser les tâches sensibles.
Que se passe-t-il ensuite ? Le processeur, avant de pouvoir réaliser l’action qui lui a été demandé, doit sauvegarder son état interne afin d’être en mesure de le restaurer plus tard et reprendre son exécution interrompue. Pour cela, il utilise généralement sa pile système où il va empiler les registres :
- EFLAGS : contenant des bits d’état du processeur (résultats d’opérations arithmétiques, indicateurs d’overflow, de signe…)
- CS (code segment) : pointe vers le segment de code en cours d’exécution
- EIP (instruction pointer) : contient l’adresse de la prochaine exécution (est incrémenté au fil des exécutions)

Call Stack
La pile d’exécution (call stack en anglais) est une structure essentielle pour pour suivre de manière cohérente l’exécution des programmes. Elle stocke les données locales à une procédure et garantie qu’au fil des appels entre procédures, on retrouvera à la fin de l’exécution de chacune l’état de la précédente.
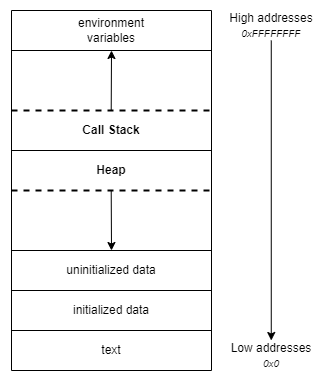
Cette pile est à mettre en perspective dans une vision plus globale de l’organisation mémoire d’un système. La taille de la pile d’exécution croit vers le bas tandis que la taille du tas (heap en anglais) croit vers le haut. Ainsi, à mesure que la pile d’exécution grandit, la valeur des adresses allouées par le tas diminuent. Le fait que les deux structures de données croissent dans un sens contraire permettent d’assurer qu’il n’y aura jamais de superposition entre les données et élimine ainsi le risque de corruption qui en résulterait. Le fait que la pile croisse vers le bas et le tas vers le haut sont de simples conventions, cela pourrait tout à fait être l’inverse.
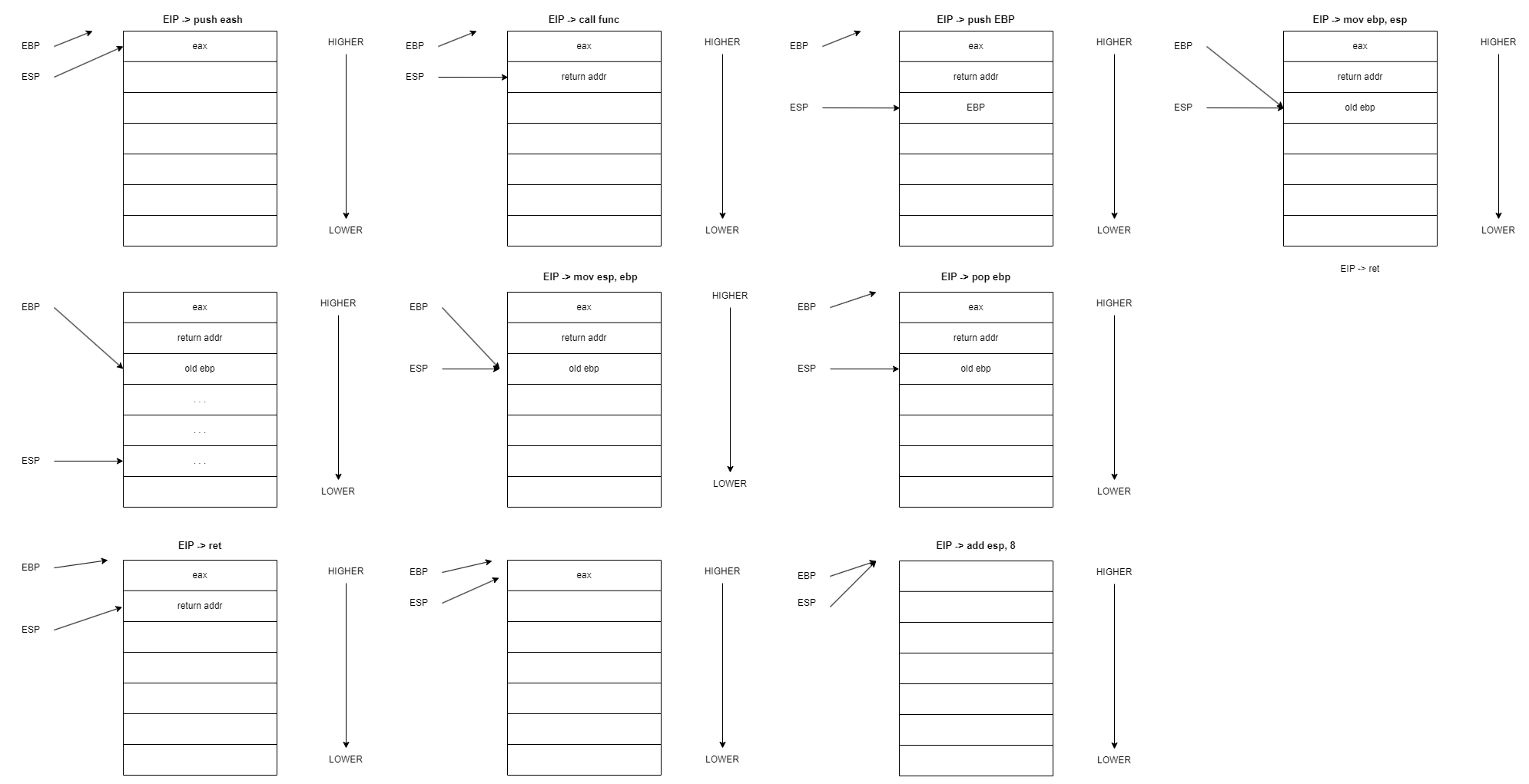
Pour mettre en œuvre cette pile d’exécution, plusieurs registres lui sont dédiés
- EIP : est un pointeur d’instruction qui suit les différentes étapes d’une procédure
- ESP : garde en mémoire l’adresse du haut de la pile (la plus basse) et est donc mis à jour à chaque ajout d’un élément dans la pile
- EBP : garde en mémoire l’adresse du début de la stack, ce qui permet notamment de retrouver l’étage permettant le retour à l’appelant de la procédure courante
On peut voir ci-dessous la section d’opérations faites dans la pile lors de l’exécution d’une procédure
push eax
call func
add esp, 8
;func(int a)
push ebp
mov ebp, esp
...
mov esp, ebp
pop ebp
retAu départ, la pile est déjà dans un certain état.
- Le registre ESP pointe sur un segment supérieur et le registre ESP sur le registre EAX contenant des informations quelconques.
- Le registre EIP pointe vers la prochaine instruction et appelle une fonction. L’adresse de retour est mise dans le registre EBP et le registre ESP est décrémenté pour descendre sur l’instruction courante.
- On suppose qu’une séquence d’instruction est maintenant décrite par la procédure func, comme des paramètres stockés, variables locales stockées, ainsi que diverses opérations.
- À la fin de cette procédure, on retourne à l’appelant en accédant au contenu du registre EBP contenant l’adresse de retour.
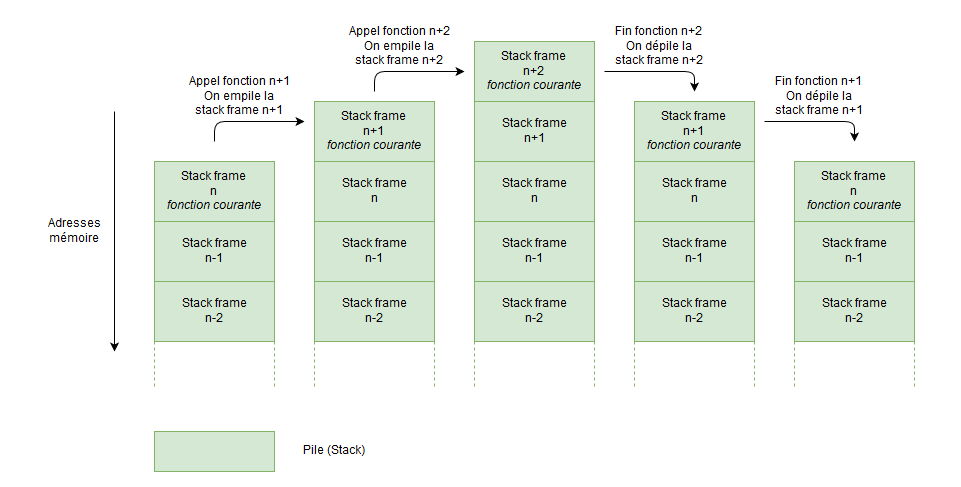
Chaque entité contenant une adresse de retour, des paramètres et autres instructions propres à une procédure constitue un “block stack frame”.
Afin de pouvoir tester le bon fonctionnement de nos appels système, le moyen le plus simple est de pouvoir réaliser des affiches avant, pendant et après l’interruption.
Framebuffer
Le framebuffer permet d’afficher du texte à l’écran en modifiant directement la mémoire. Il est constitué de 80 colonnes et de 25 lignes. La zone de la mémoire correspondant au framebuffer peut être représentée comme un tableau d’entiers de 16 bits. Chaque case de ce tableau représente un caractère.
Les 8 premiers bits de chaque case sont utilisés pour stocker le code ASCII du caractère que l’on souhaite afficher.
Il est également possible de choisir la couleur des caractères ainsi que la couleur de l’arrière-plan de ceux-ci. C’est ici que les 8 derniers bits de chaque case entrent en jeu:
- les 4 premiers codent la couleur du caractère
- les 4 suivants codent la couleur de l’arrière-plan du caractère
Pour écrire un caractère à l’écran on peut utiliser le code suivant:
/*
* Writes the specified character at the specified offset
*
* @param pos The position at which to prints the character
* @param c The character to display
* @param fg The foreground color of the character
* @param bg The background color of the character
*/
static void fb_write_char(unsigned int i, char c, unsigned char fg, unsigned
char bg) {
fb[i * 2] = c;
fb[(i * 2) + 1] = ((bg & 0x0F) << 4) | (fg & 0x0F);
}Dans l’architecture x86, le framebuffer se situe à l’adresse 0xB8000
Avec toutes ces informations en main, il est désormais possible d’écrire quelques fonctions permettant d’afficher du texte à l’écran facilement (faire en sorte que l’écran défile tout seul, retour automatique à la ligne, etc.).
Maintenant que nous avons présenté un certain nombre des composantes de base d’un noyau, voyons comment il est possible de les combiner pour produire un exécutable compréhensible par un ordinateur.
Comment compiler le noyau ?
Afin que notre noyau soit bootable, il est nécessaire de produire un fichier au format ISO contenant GRUB. GRUB nous permet de localiser en mémoire les structures de donnée dont nous auront besoin par la suite.

Afin que le code de notre noyau puisse être localisé en mémoire par GRUB, il doit être chargé en mémoire après ce dernier, GRUB devant obligatoirement être le point d’entrée du fichier. Un fichier de configuration est donc necéssaire afin de donner cette directive au linker.
ENTRY(loader) /* the name of the entry label */
SECTIONS {
. = 0x00100000; /* the code should be loaded at 1 MB */
.text ALIGN (0x1000) : /* align at 4 KB */
{
*(.text) /* all text sections from all files */
}
.rodata ALIGN (0x1000) : /* align at 4 KB */
{
*(.rodata*) /* all read-only data sections from all files */
}
.data ALIGN (0x1000) : /* align at 4 KB */
{
*(.data) /* all data sections from all files */
}
.bss ALIGN (0x1000) : /* align at 4 KB */
{
*(COMMON) /* all COMMON sections from all files */
*(.bss) /* all bss sections from all files */
}
}On observe ici les différentes sections du programmes nécessaire à l’exécution:
- text: contient le code
- data: contient les données (variables) du programme
- rodata: contient les données en lecture-seule (Read-Only)
- bss: Block Starting Symbol, contient les variables qui n’ont pas été initialisées
On indique ici que le noyau doit être chargé à 1 Mio.
Comment compiler les programmes ?
Par défaut, la compilation d’un code source C à l’aide du compilateur GCC produit un fichier exécutable au format ELF. Or, l’exécution d’un tel programme nécessite un grand travail préliminaire: lecture des différentes sections mémoires décrites par le fichier, préparation des segments mémoire nécessaires etc. L’intérêt du projet n’étant pas d’écrire une interface permettant de manipuler le ELF, il a été décidé d’utiliser des flat-binary dont la représentation est bien moins complexe.
Cette façon de faire a pour avantage de déléguer une très grande partie d’exploration de la mémoire à GRUB qui nous fournit un certain nombre de structures permettant de localiser les programmes en mémoire. Ce mécanisme est d’ordinaire réservé à ce qu’on appelle les modules noyau qui sont chargés d’effectuer des actions qui n’ont pas été embarquées dans le noyau de base. L’avantage de cette méthode est que l’on a ici accès directement aux données
Bibliographie
- Modern Operating Systems – Andrew S. Tanenbaum
- The Little book About OS Developpement – Erik Helin & Adam Renberg
- The logical design of operating systems – Lubomir Bic & Alan C. Shaw
- ia-64 linux kernel, design and implementation – David Mosberger & Stephane Eranian
- The design of the UNIX operating system – Maurice J. Bach
- Operating System Design: The XINU Approach – Douglas Comer
- Linux Source Code
