
Vous en avez marre de travailler pour MacDo ? Marre de donner des cours à des sales mioches sur Acadomia ? Marre de livrer des Pizzas avec Deliveroo ? N’attendez plus de traverser la rue ! Je vous propose maintenant de réussir votre entretien de DevOps Junior en BigData en apprenant le strict minimum sur les composants de bases d’un ordonnanceur de containers bien connu : Kubernetes.
À quoi sert Kubernetes ?
Pour faire simple, dans la conjecture actuelle, le paradigme de développement de projet repose sur la gestion de container. Vous n’êtes pas sans savoir que les containers sont des objets englobant le code et ses dépendances pour pouvoir être exécuté rapidement et de manière fiable d’un environnement à l’autre. Pour un plus gros projet, il est tout à fait envisageable d’avoir à gérer plusieurs containers en même temps. Vous aurez besoin d’outils vous permettant la mise à l’échelle, la fiabilité, interopérabilité, la résilience aux pannes : ainsi viennent naturellement les orchestrateurs de containers comme le très populaire Kubernetes.
Kubernetes Master : Le centre de commandement.
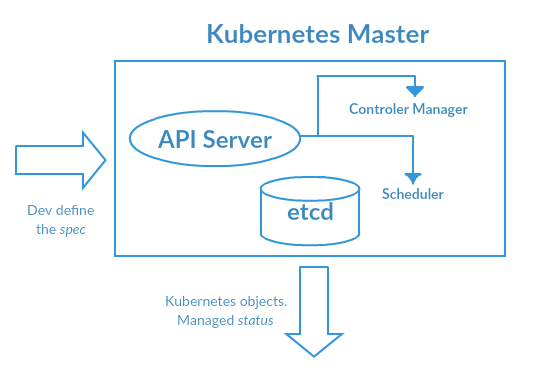
Ce n’est pas une définition à apprendre par cœur, mais un moyen de visualiser le fonctionnement de Kubernetes est d’imaginer un centre de commandement. Le Kubernetes Master prend en entrée une configuration de l’état du système et en sortie va opérer l’orchestration sur les containers.
réalisée par un membre du groupe
Plus concrètement le développeur va configurer Kubernetes à l’aide de l’API Server. Comme tout bon C&C (Command and Center) qui se respecte, nous allons avoir une interface Web nous permettant de configurer et d’auditer notre projet à l’aide d’une batterie de requête HTTP. Ainsi, souvent à l’aide de fichier au format JSON le développeur sera capable de configurer la charge de travail des containers
À l’aide de ces fichiers de configuration, nous pourrons paramétrer le Controller Manager (Qui permet de contrôler notre ensemble de containers) ainsi que le Scheduler qui permet de sélectionner les containers à démarrer tout en évaluant la disponibilité des ressources.
Sans rentrer dans les détails, l’etcd est l’unité de stockage permettant d’identifier rapidement nos containers en temps réel. Il est nécessaire d’avoir une telle base de données très réactive pour laisser l’opportunité à notre Master d’opérer sur nos containers qui ont un comportement par définition très volatile.
Les objets Kubernetes.
Un objets Kubernetes est une entité persisistance d’un cluster Kubernetes (comprenez l’ensemble manipulable par Kubernetes qui va contenir notre projet). Il existe une large gamme d’objets qui peuvent représenter toutes sortes d’informations sur nos containers. Allant de : savoir quelle applications est conteneurisées, leur consommation à et leur politiques attribuées (Par exemple la mise-à-jour, le comportement attendu lors d’une panne ou bien le redémarrage).
Pour créer un objet, vous devez définir sa spec. Dans le champs spec vous allez donner des informations concernant l’état désiré de votre objet ainsi que d’autres informations (comme le nom, la version de l’application conteneurisée, le nombre de réplication s’il s’agit d’un Pods, parfois le ports etc.). Le rôle du Kubernetes Master ici est de faire converger l’état de notre objet courant à l’état désiré. Autrement dit, le Controller Manager et le Scheduler doivent à tout moment maintenir (ou faire évoluer) le champs status à l’état désiré.
Sachez seulement que pour créer un tel objet, vous allez devoir transmettre sa spec à l’API Server. Souvent vous allez définir votre spec en .yaml. L’outil kubectl convertira ce fichier en JSON vous l’envoyer ensuite au Kubernetes Master à l’aide de l’API Server.
Afin de vous aider à épater votre futur employeur nous allons détailler quelques-uns des objets Kubernetes les plus importants : Les Pods, les labels, les selecteurs etc.
Les Pods, l’objet le plus simple de Kubernetes

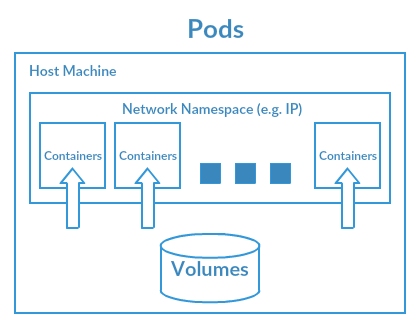
Il ne s’agit pas des entités aliens d’H. G. Wells sonnant le glas de l’humanité tout entière. Non, il s’agit en fait de l’entité la plus simple et la plus petite de Kubernetes. Cette entité représente une instance de votre application. Elle peut contenir un ou plusieurs containers.
Réalisée par un membre du groupe
Les Pods partagent les même ressources sur la machine hôte (ou la VM). On définit donc un Volume (un répertoire) commun pour les containers. Souvent on utilise un disque local ou bien le réseau. De même, les Pods partagent une unique adresse IP dans le cluster.
En pratique les Pods sont très volatiles, il ne peuvent pas avoir leur propre système de résilience aux pannes. C’est pourquoi on utilise des Controllers (tel que les Deployments, ReplicaSets et ReplicationControllers que nous verrons plus tard) pour gérer la réplication ou bien la résilience aux pannes.
Les labels et les labels selectors
Lorsque nous avons un grand nombre d’objets, pas forcément du même type d’ailleurs (Pods, Nodes, etc.), il peut se révéler utile de les mettre dans des catégories afin de faciliter l’organisation des Controllers. Pour désigner ces sous-ensembles nous utilisons un système de clé-valeur appelé label.
Un exemple de labellisation de nos objets pourrait être les clé-valeurs suivantes : app:frontend et app:backend. La clé ici est app et les valeurs sont frontend et backend. Remarquez qu’il est possible d’associer plusieurs clé différentes à un même objet Kubernetes.
Pour sélectionner nos objets Kubernetes selon leur label, vient tout naturellement le concept de labels selector. Kubernetes permet de faire deux types distincts de sélections :
- Sélecteurs d’égalité : Cette méthode permet de filtrer les valeurs des clés selon des opération binaires simples telles que l’égalité = ou == ou bien la différence !=. Avec notre exemple précédent nous pouvons par exemple sélectionner tous les objets en relation avec la partie frontend de notre application avec le sélecteur app==frontend.
- Sélecteurs ensembliste : Cette méthode permet de filtrer les valeurs des clés selon un ensemble de départ. Les opérateurs peuvent être in, notin et exist. Par exemple une telle selection pourrait ressembler à : app in (frontend, cloud)
Maintenant que nous savons ce qu’est un label. Il semble judicieux de revenir sur l’intérêt de l’etcd. Pour rappel il s’agit de l’unité de stockage du Kubernetes Master. Cette espace sert en fait à conserver les labels (clé-valeur) à tout moment. Sa mise à jour est cruciale et est indispensable pour assurer la fiabilité des opérations des contrôleurs.
Les ReplicationControllers et ReplicaSets
Peu à peu nous rentrons dans les entrailles de Kubernetes. Lors d’un entretien il s’agit de faire parler votre meilleur jeux d’acteur. Montrez que vous maîtrisez pleinement la situation. Entraînez-vous à dire plusieurs fois ReplicationControllers de manière fluide, puis n’oubliez pas de préciser qu’il est d’usage d’utiliser l’acronyme RC. Vous aurez l’air d’un vrai pro !
Ainsi le ReplicationControllers fait partie du Kubernetes Master vu précédemment (celui avec le premier schéma bleu réalisé en toute modestie par un membre de notre groupe). C’est lui qui se charge d’ajuster le nombre de réplications d’un Pod à tout moment. Plus généralement nous ne déployons pas de Pods sans faire intervenir des modules comme ce contrôleur.
Le ReplicaSets est une version amélioré du ReplicationControllers. Le ReplicaSets prend en charge les sélecteurs d’égalité et les sélecteurs ensemblistes tandis que le ReplicationControllers ne prend pas en charge les sélecteurs ensemblistes. N’oubliez pas de surprendre votre futur employeur en précisant bien qu’il est d’usage d’utiliser l’acronyme RS pour ReplicaSets. Exhiber votre culture comme vous le feriez si vous deviez étaler sur votre tartine un maigre reste de confiture.
Les services Kubernetes
Comme nous l’avons dans la section concernant les Pods, ces derniers sont volatiles et ne peuvent pas être résiliants aux pannes. Ils sont mortels, lorsque les Pods meurent ils ne sont pas ressuscités. C’est par exemple le rôle du ReplicatSets (lors d’une mise à l’échelle) de dynamiquement créer ou supprimer des Pods. Par ailleurs, comme nous l’avons déjà vu, lors de la création d’un Pod, on lui associe une unique adresse IP. Or les autres objets du cluster ne devrait pas tenir à jour une liste de ces adresses, ils ont besoin d’une abstraction.
Cette abstraction est fournie par les services. Un service (aussi appelé un micro-service) est une abstraction qui permet de définir un ensemble logique de Pod ainsi que des règles d’accès. L’ensemble des Pods utilisé dans un service est déterminé par un label selector. En pratique l’objet qui aura besoin d’utiliser une application en particulier s’adressera à son service associé et non à l’application directement.
Il arrive parfois qu’on veuille créer un service sans label selector au profit d’une configuration manuelle. Sachez simplement que ce scénario est possible et que vous allez devoir définir vous même votre communication avec des adresses IP et des ports. Par exemple si vous travaillez sur une base de données locale pour vos tests mais sur une base de données externe en production vous aurez besoin de définir ce genre de service sans sélecteur.
Le DeploymentController et les Deployments
Tout comme le ReplicationControllers, le DeploymentControllers fait partie du Kubernetes Master. Il s’assure de toujours faire converger l’état actuel vers l’état désiré. Un objet Kubernetes Deployment lui permet de spécifier une création ou bien une mise à jour de Pods et de ReplicaSets pour une application donnée.
Les Namespaces
Lorsque nous avons plusieurs équipes composées elles-même de plusieurs personnes sur des plus gros projets. Il peut être pratique de diviser le cluster en sous-cluster. Pour cela nous utilisons des Namespaces, le nom des objets à l’intérieur d’un Namespace est unique, mais Kubernetes n’exige pas cette unicité entre plusieurs Namespace.
Il n’est pas recommencé d’utiliser des Namespaces si votre équipe ne dépasse pas les 10 membres. Dans le cas d’une légère division de votre projet, privilégiez plutôt les labels si vous séparez les ressources.
Les Noeuds
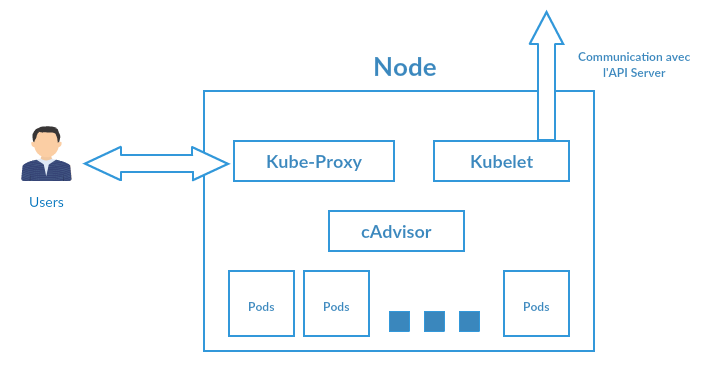
Les Noeuds, les Workers ou encore les Minions sont dans Kubernetes une abstraction permettant de regrouper un ensemble d’objets et d’éléments de contrôle et de transport tel que le Kubelet et le Kube-Proxy. Avec le concept de nœuds, nous pouvons redéfinir la notion de cluster Kubernetes simplement comme un ensemble de nœuds, chacun étant sur des machines uniques (VM ou physique) et communiquant avec le Kubernetes Master.
Réalisée par un membre du groupe
- Kubelet : Outil qui se veut pragmatique, il permet de gérer les containers. Il peut les mettre en marche ou en arrêt. Il permet la maintenance en surveillant les Pods et prévient les maîtres en cas d’anomalie. Auxquels cas Les Contrôleurs dans le Kubernetes Master décideront quoi faire.
- cAdvisor : Dans un nœud, ce module permet de faire du monitoring sur le processeur, la mémoire, le trafic réseau et le disque. Sur chaque module il agit comme une sonde qui permet de récolter les précieuses informations utilisées par le Kubelet
- Kube-proxy : Permet le routage du trafic réseau vers l’extérieur et vers l’intérieur du nœud.
Il vous reste encore beaucoup à apprendre sur Kubernetes. Cependant, vous êtes suffisamment armé pour confectionner une magnifique broderie d’arguments pour persuader votre futur employeur que vous possédez une certaine maîtrise de Kubernetes. Une dernière petite remarque : parfois nous utilisons l’abréviation k8s pour désigner Kubernetes, le 8 désigne le nombre de lettres se situant entre le K du début et le S de la fin qui est de … 8 !
Mohammed Ansari, Elhadj Amadou Diallo, Samy Metadjer, Cheikh Sall
