Hadoop
Hadoop est un framework libre et open source écrit en Java, qui permet aux applications de travailler avec des milliers de nœuds de calcul et des données très volumineuses.
Il utilise le modèle de programmation MapReduce pour stocker, traiter et récupérer plus rapidement les données dans ses nœuds. Son développement a été inspiré par la publication de MapReduce, GoogleFS (google file system) et BigTable de Google. Il a été créé par Doug Cutting et fait partie des projets de la fondation logicielle Apache depuis 2009.
1 – Prérequis
Pour installer Hadoop sur n’importe quel système, assurez-vous que Java est installé. Si Java n’est pas installé sur votre système Linux, utilisez la commande qui suit pour l’installer.
En tenant compte de la documentation de hadoop.3.2.1 sur le site officiel le mieux est d’utiliser java 8 , la version la plus stable.
Avoir en main le module ssh, qui lui aussi nécessaire à la bonne communication entre les nœuds, est utile.
belak@belak: sudo apt-get install openjdk-8-jdk belak@belak: sudo apt-get install ssh
2 – Créer un utilisateur
Pour cela il nous faut exécuter quelques commandes à fin de créer et configurer un compte utilisateur (user) réservé à Hadoop. On peut aussi ne pas le faire, mais pour la bonne pratique le recommande. Vous trouverez ci-dessous la commande nécessaire pour Linux :
belak@belak: adduser hadoop
Après avoir créé le compte, on a également à configurer ssh. Pour ce faire, on se positionne en tant qu’utilisateur hadoop, pour exécuter ce qui suit et qui permet de générer une paire de clés ssh , on vous demandera d’accepter de copier la clé public dans le fichier known_hosts :
belak@belak: su - hadoop hadoop@belak: ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa hadoop@belak cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys hadoop@belak chmod 0600 ~/.ssh/authorized_keys
Maintenant, on peut se connecter au localhost pour tester la bonne configuration du compte utilisateur qu’on a créé (hadoop).
Cette commande ne devrait pas demander le mot de passe par contre, ça nous demandera d’ajouter la clé à la liste des hôtes connus.
hadoop@belak: ssh localhost
3 – Téléchargement et installation
http://mirror.ibcp.fr/pub/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
En allant sur le site officiel de Apache Hadoop, en suivant les liens de téléchargement (Download) vous trouverez des liens de téléchargement. Choisissez la version binaire (binary).
Attention, le téléchargement est assez lourd, le fichier pèse environ 400Mo.
Une fois le fichier téléchargé, on le copie vers son répertoire d’installation:
belak@belak: sudo mv hadoop-3.1.1 /usr/local/hadoop
Ensuite, on met donne la propriété des fichiers à l’utilisateur :
belak@belak: sudo chown hadoop /usr/local/hadoop
Ceci fai , on s’intéresse à mettre à jour les variables d’environnement, afin d’assure à Haddop un bon fonctionnement. Il faut d’abord éditer le fichier .bashrc, par exemple avec gedit(mais tut autre éditeur de texte fera l’affaire) :
belak@belak: su hadoop hadoop@belak: gedit ~/.bashrc
et y ajouter les lignes suivantes (de préférence à la fin du fichier) , noté bien que HADOOP_HOME dépendra de votre répertoire d’installation.
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
4 – Configuration d’Hadoop
Avant toute utilisation, on doit d’abord configurer quelques fichiers, qui se trouveront dans le répertoire de votre installation , notamment les fichiers:
etc/hadoop/core-site.xml etc/hadoop/mapred-site.xml etc/hadoop/hdfs-site.xml etc/hadoop/yarn-site.xml
Pour ce faire , vous devez éditer les fichiers cités ci-dessus et copier les contenus qui suivent :
hadoop@belak: gedit etc/hadoop/core-site.xml
Cette propriété fournit l’adresse(le port) du système HDFS (hadoop file system) à nos commandes dfs(distributed file system) .
Si ce n’est pas spécifié, nous aurions besoin de donner l’adresse HDFS dans chacune des commandes dfs.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop@belak: gedit etc/hadoop/mapred-site.xml
Les options de configuration de MapReduce sont stockées dans ce fichier sont modifiables et remplacent les valeurs par défaut des paramètres MapReduce.
<configuration> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration>
hadoop@belak: gedit etc/hadoop/hdfs-site.xml
C’est le fichier qui configure où le NameNode ( le shérif du système qui maintient l’ordre dans les méta-données et distribue les tâches) va stocker l’historique des transactions et où les DataNode (est un worker. Cela veut dire qu’il effectue les opérations demandées par namenode)vont stocker leurs blocks. C’est également ici où le coefficient de réplication est configuré.
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/data/nameNode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/data/dataNode</value> </property> </configuration>
hadoop@belak: gedit etc/hadoop/yarn-site.xml
Yarn Il permet de gérer les ressources du système et de planifier les tâches.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5 – Démarrage et exécution
Maintenant place aux choses sérieuses : « l’exécution » ;on pourra lancer notre cluster Hadoop à l’aide des scripts fournis par ce dernier. Accédez simplement à votre répertoire $HADOOP_HOME/sbin et exécutez les scripts un par un.
Nous devons d’abord formater le système de fichiers de Hadoop , sachez que c’est des script qui sont déjà prêt :
hadoop@belak: hdfs namenode -format
ensuite, une fois le système de fichiers formaté, on pourra lancer les daemons hadoop. Pour cela il fut se déplacer dans $HADOOP_HOME/sbin (voir la valeur exacte de la variable au-dessus) :
hadoop@belak: cd /usr/local/hadoop/sbin
Dans ce répertoire, vous trouverez les scripts à lancer, un par un :
hadoop@belak: ./start-dfs.sh hadoop@belak: ./start-yarn.sh
ou tout à la fois :
hadoop@belak: ./start-all.sh
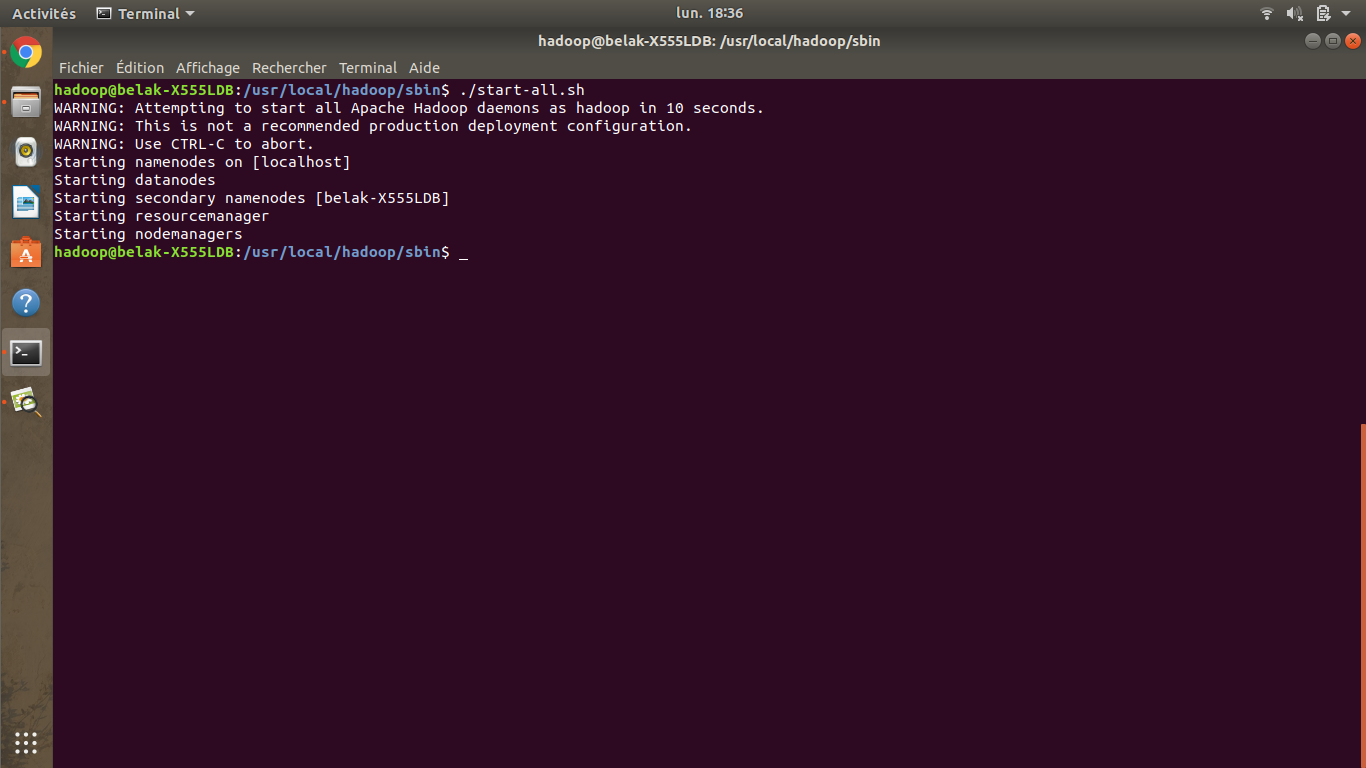
Si vous avez bien configuré vos fichiers, en suivant les étapes indiquées ci-dessus, votre cluster se lancera de cette manière.
Hadoop fournit une interface web de gestion. On peut y voir la configuration, l’état d’avancement de nos projets lancés, les fichiers sauvegardés sur le système de fichier Haddop. C’est consultable aux urls suivantes :
http://127.0.0.1:9870/ http://127.0.0.1:8042/
Notamment il faut savoir aussi que ces numéros de port sont part défaut , on peut les changer en modifiant le fichier :
hadoop@belak: cd /usr/local/hadoop/etc/hadoop/ hadoop@belak: gedit hdfs-site.xml
en ajoutant la balise xml suivante , mettre le numéro de port dans value aprés localhost:
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50000</value>
<final>true</final>
</property>
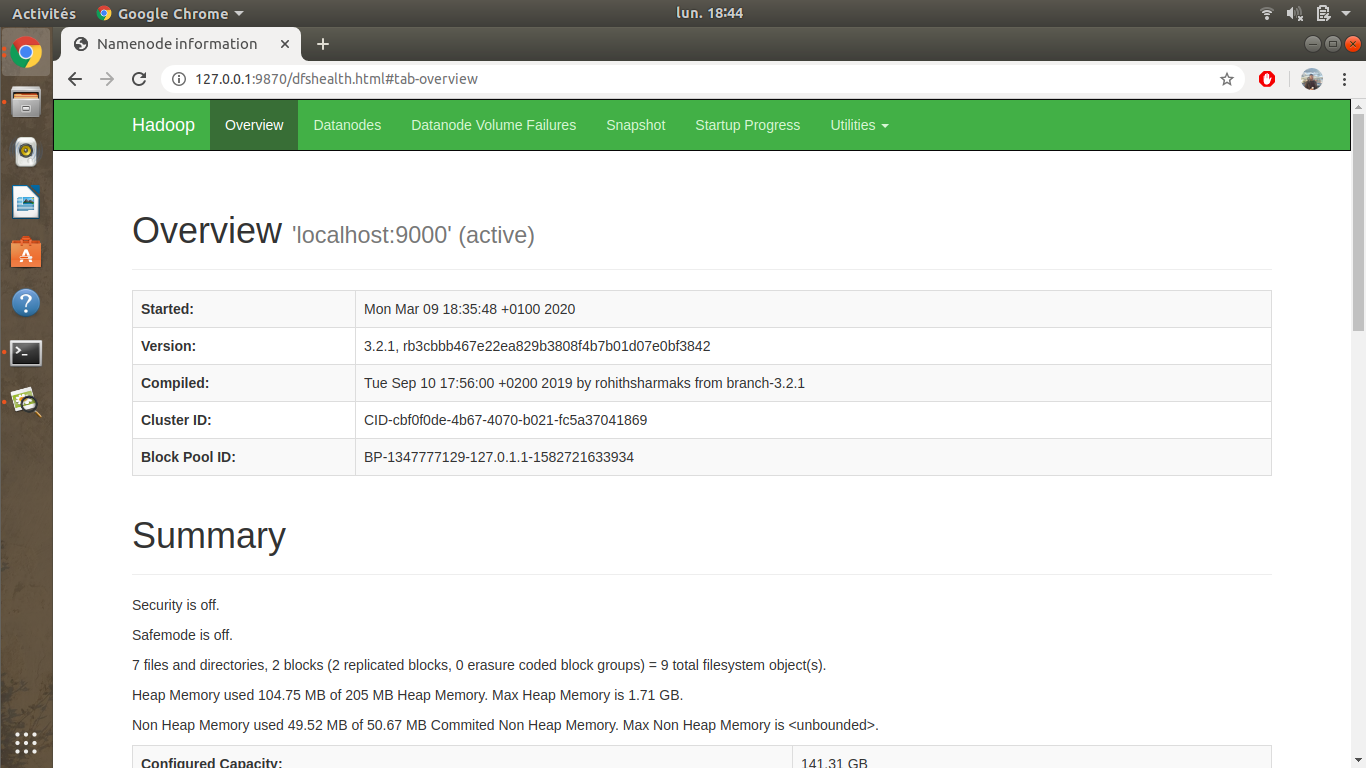
6 – Exemple de test (en Python)
Nous atteignons enfin le but ultime de ce tutoriel, pour finalement arriver à voir du concret : un calcul qui prend place dans Hadoop.
Je me place d’abord dans le répertoire racine de Hadoop, où je vais créer un répertoire qui s’appellera user, ensuite, deux autres sous-répertoires pour contenir les données d’entrées et les sorties produites, qui se nommeront respectivement input et output .
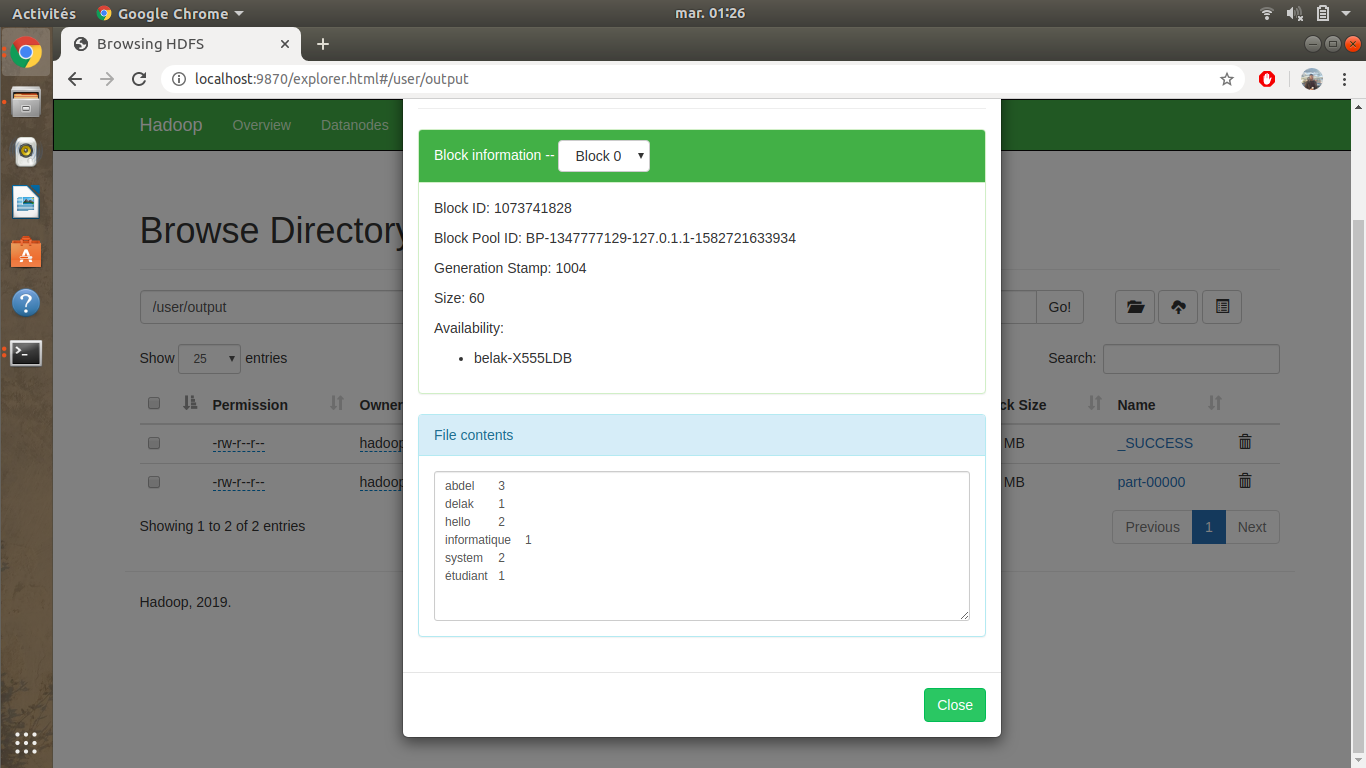
Dans cet exemple nous essayons de faire un compteur de mots (word count). Étant donné une liste de phrases, au final on va construire une liste de couples <mot,nombre d'occurence>. Je présente le petit bout de code en python que j’ai partagé selon le patron de conception MapReduce, avec deux scripts principaux : Mapper et Reducer.
mapper.py
#!/usr/bin/env python
import sys
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
print ('%s\t%s' % (word, 1))
reducer.py
#!/usr/bin/env python
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
# remove leading and trailing whitespaces
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
if current_word == word:
current_count += count
else:
if current_word:
print ('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
if current_word == word:
print ('%s\t%s' % (current_word, current_count))
En créant ces deux fichiers python, assurez vous qu’ils sont bien nommé “mapper.py et reducer.py”,
Passant à l’étape suivante qui consiste à créer le répertoire user ,et à l’intérieur les répertoires input et ouput :
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/input $ bin/hdfs dfs -mkdir /user/output
Les répertoires input et output servirons comme leurs noms l’indique aux entrées et sorties de notre application. Quand tout ça est prêt, on crée un fichier test.txt d’entrée sur lequel s’effectuera le comptage des mots, on le place donc dans le système de fichiers de Hadoop :
$ bin/hdfs dfs -put test.txt /user/input
Maintenant que tout prêt, il nous restera juste à exécuter le script qui lancera les calculs dans Hadoop, mais faut faire attention, il nous faut désactiver le mode safemode de Hadoop qui restreint la modification des hdfs (hadoop file system)
$ hadoop dfsadmin -safemode leave
Finalement, voila le script à lancer, faites bien attention à respecter la syntaxe :
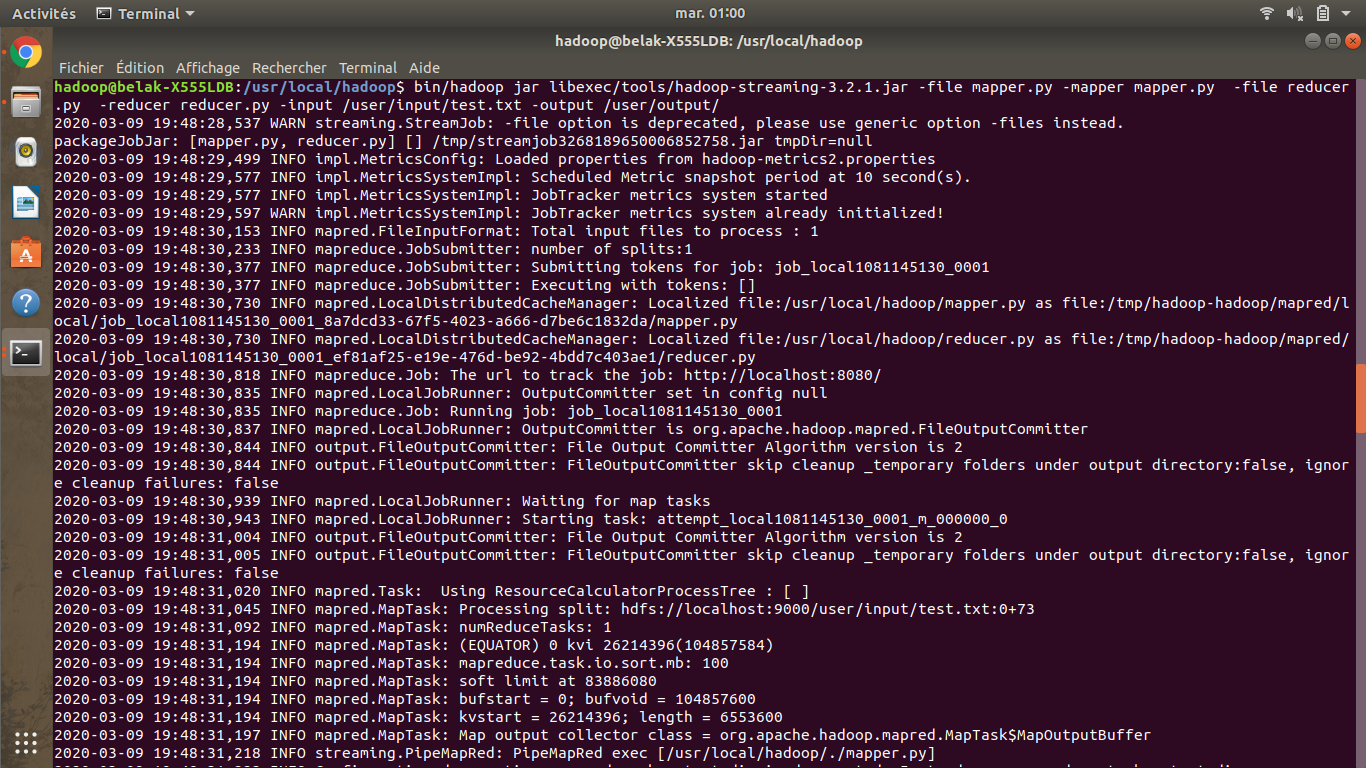
$ bin/hadoop jar libexec/tools/hadoop-streaming-3.2.1.jar -file mapper.py -mapper mapper.py -file reducer.py -reducer reducer.py -input /user/input/test.txt -output /user/output/
Vous remarquez bien qu’on a utilisé une bibliothèque Java pour pouvoir lancer ce programme python (hadoop-streaming-3.2.1.jar). Elle nous permet de lancer n’importe quels script en forme de mapper et de reducer.
Le résultat est le suivant.
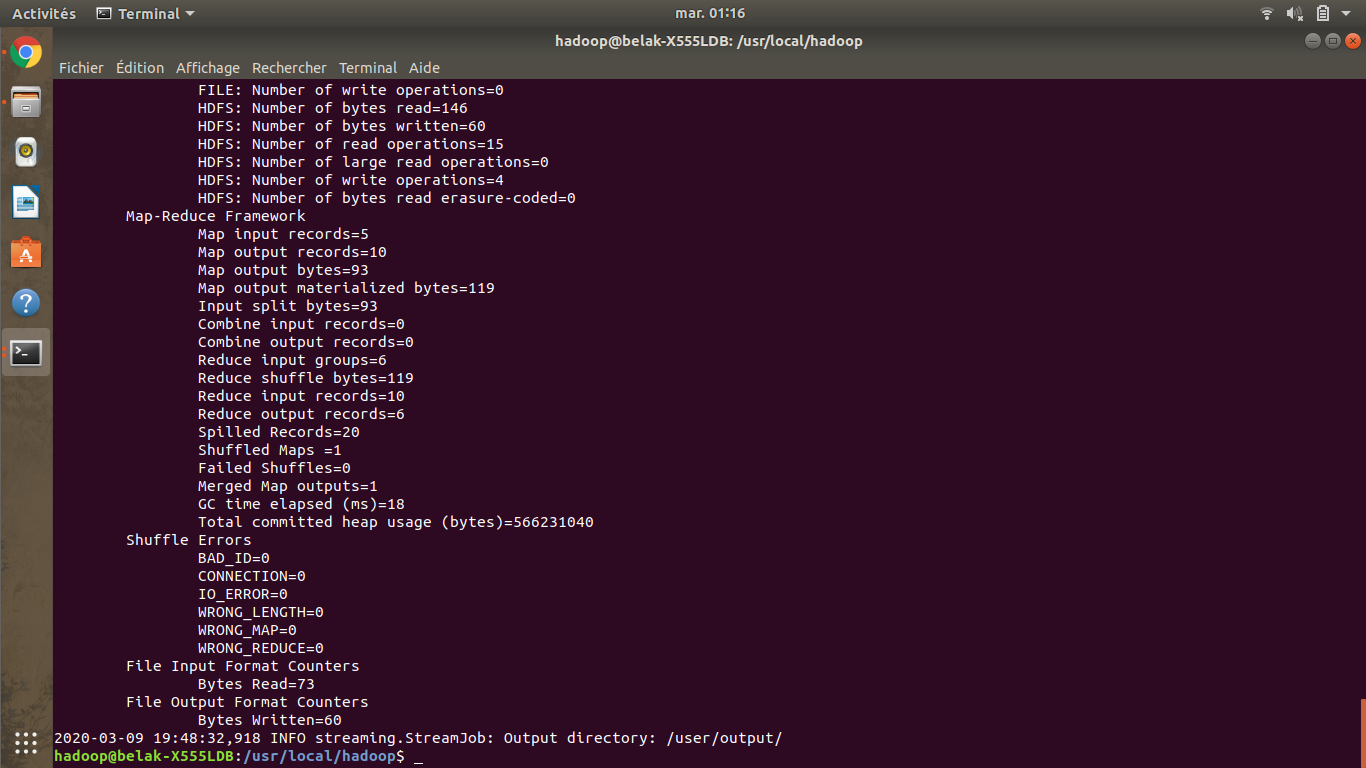
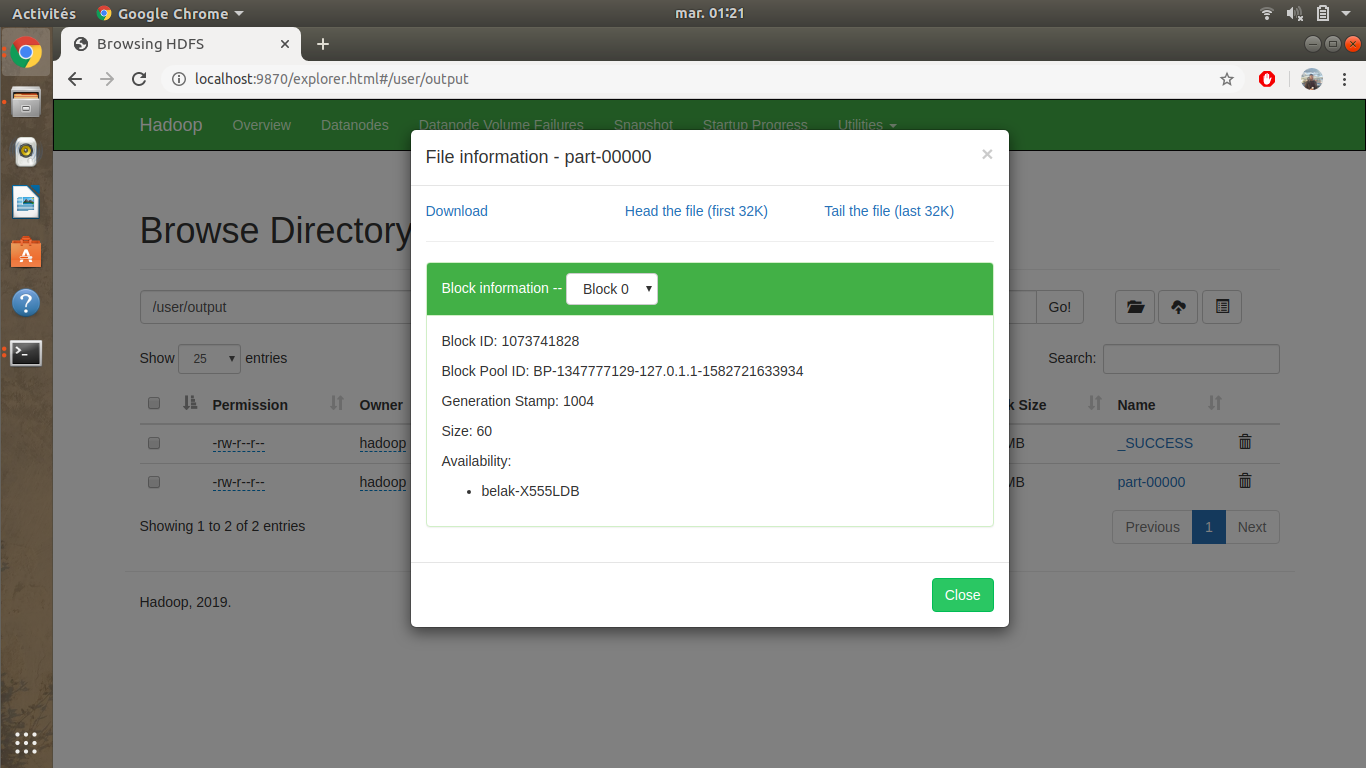
Vous aurez à la fin de l’exécution un résultat identique sur votre terminal, et pour visualiser le résultat du programme WordCount utilisé, il suffit d’aller sur le lien ci-dessous et ensuite cliquer sur output , part-00000 et finalement sur head the file
http://localhost:9870/explorer.html#/
7- Erreurs récurrente
Aucune installation ne se passe comme prévue , chaque système à ça spécificité , lors de mon installation j’en ai rencontrer quelques unes , cependant celles-ci :
N’hésitez pas à me contacter par mail pour toutes questions.
