
Dans cet article, nous allons nous intéresser à la virtualisation du stockage mais avant tout, qu’est ce que la virtualisation ?
La virtualisation est une couche d’abstraction informatique qui permet de faire fonctionner plusieurs serveurs, systèmes ou applications sur un même serveur physique (tout dépend du type de virtualisation choisie).
La virtualisation a donc permis par ce processus d’ouvrir de nombreuses portes, et constitue la pierre angulaire du Cloud.
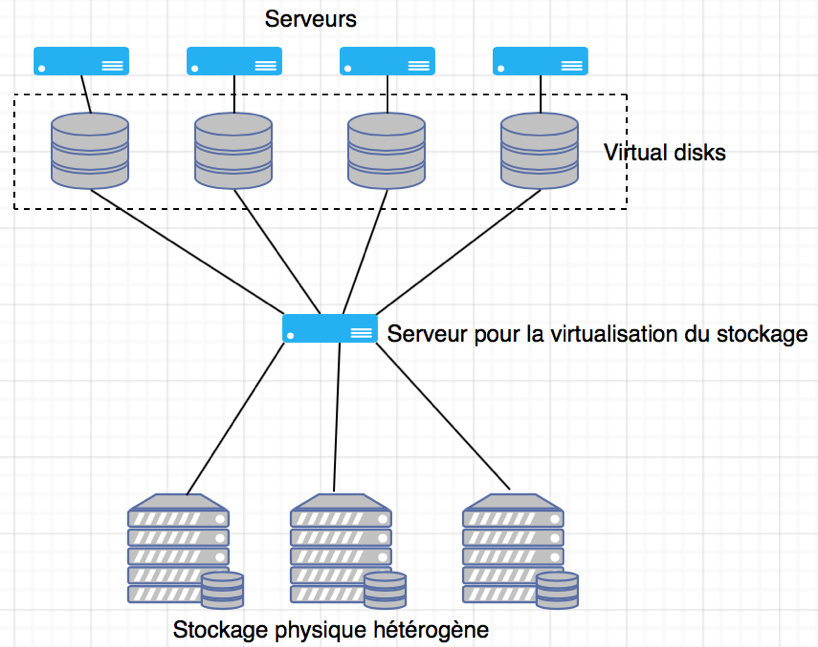
Ainsi, les technologies qui virtualisent le stockage physique dans un réseau de stockage (SAN) en disques virtuels accessibles par les applications et les données. Ce «partitionnement» permet la consolidation de fournisseurs et de protocoles mixtes et permet le partage des ressources de stockage. La virtualisation de plusieurs machines physiques et/ou l’utilisation d’une seule machine physique avec plusieurs machines virtuelles est un excellent moyen d’étendre l’utilisation de l’espace disque actuel, de résoudre les problèmes de déduplication et de redondance et de réduire les coûts d’exploitation à long terme.
Mais à quelle problématique ce type de virtualisation répond-elle et pourquoi vouloir y recourir?

Avec les usages actuels des moyens informatiques, le stockage des données peut poser problème :
- le volume de données croît sans cesse,
- les applications exigent plus de performances
- et le nouveau matériel est difficile à intégrer.
Les environnements de stockage typiques utilisent plusieurs périphériques de différents fabricants mais ils ne peuvent que difficilement communiquer entre eux. Il est compliqué de les gérer de manière centralisée, ils fonctionnent ainsi en silos et deviennent rapidement obsolètes en quelques années.
La virtualisation de stockage regorge de bénéfices.
Parmi ces bénéfices, on retrouve un élément important qui est la souplesse.
Ainsi, grâce à ce type de virtualisation nous avons la possibilité de stocker une donnée sur le support le mieux adapté à ses contraintes d’accès et de la déplacer sans impact. Elle permet aussi de mieux utiliser les capacités de stockage.
Types de virtualisation du stockage
La virtualisation de stockage se compose de deux catégories :
La virtualisation des blocs : Les systèmes basés sur des blocs font abstraction du stockage logique et sépare celui-ci du stockage physique afin que l’utilisateur / administrateur puisse y accéder sans avoir à accéder au stockage physique, ce qui donne à l’administrateur plus de flexibilité dans la gestion des différents stockage. Cela permet au logiciel de gestion de la virtualisation de collecter la capacité des blocs d’espace mémoire disponibles et de les regrouper en une ressource partagée à affecter à n’importe quel nombre de machines virtuelles, de serveurs bare-metal ou de conteneurs.
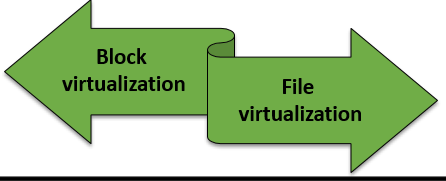
La virtualisation des fichiers : Appliqué aux systèmes de stockage en réseau (NAS). À l’aide des protocoles SMB (Server Message Block) ou NFS (Network File System), elle élimine la dépendance entre l’emplacement physique et les données accessibles au niveau des fichiers afin d’optimiser l’utilisation du stockage et effectuer des migrations de fichiers sans interruption
Méthodes de virtualisation
La virtualisation réfère généralement à la mise en pool des différents stockages disponibles et à leur conservation dans un seul stockage dans un environnement virtuel, les technologies récentes utilisent non seulement le stockage virtuel mais aussi l’alimentation et le réseau. Mais alors, quelles sont les différentes façons dans lesquelles ces stockages peuvent êtres utilisés dans un environnement virtuel ?
L’approche basée sur l’hôte : Ici, la virtualisation se fait au niveau de l’hôte, où nous présentons à l’utilisateur un stockage virtuel avec différents ensembles de capacités où les hôtes sont multiples, que l’utilisateur se serve d’une machine personnelle ou virtuelle qui accède au stockage en ligne ne change rien. La virtualisation se fait à l’aide d’un logiciel et pour notre stockage physique, nous pouvons utiliser n’importe quel appareil. Les principaux points positifs de cette approche sont sa simplicité de conception et de codage, il peut prendre en charge tout type de stockage et aide à améliorer l’utilisation de celui-ci, par ailleurs il dispose d’un logiciel unique pour chaque système d’exploitation, la synchronisation de l’hôte est une tâche difficile et l’optimisation ne peut être effectuée que sur une base de coût.
L’approche basée sur les baies : Dans cette méthode, notre stockage apparait comme un ensemble de périphériques qui représente le stockage physique, où généralement ces stockages sont constitués de disques durs HDD (Hard Disk Drive) et SSD (Solid State Driver). Différents logiciels sont utilisés pour gérer ces baies de stockage et masqués au niveau utilisateur/ invité. Quelques avantages de cette méthode est que nous n’aurions besoin d’aucun type de matériel/infrastructure supplémentaire et qu’il n’y a aucune latence pour assister à une E/S particulière.
L’approche basée sur le réseau : Largement utilisée aujourd’hui dans de nombreuses grandes entreprises. Dans cette approche, on utilise un Fiber Channel dans lequel tout périphérique réseau tel qu’un serveur spécifique ou un commutateur intelligent, se connecte à un SAN (réseau de stockage) et sera représenté comme un pool de stockage virtuel pour l’utilisateur invité. Le principal avantage de cette approche est qu’elle aide à atteindre la véritable forme de virtualisation hétérogène, aide à améliorer les performances, un seul appareil de gestion pour tout le stockage impliqué et qu’il est facile de répliquer les services sur tous les appareils.
Configurations de la virtualisation du stockage
L’approche intrabande (symétrique) : Dans cette méthode, nous stockons la configuration de l’environnement virtuel dans le chemin de données lui-même comme dans les données ainsi que le flux de contrôle. Ce type de solution est considéré comme facile / simple à mettre en œuvre car nous n’utilisons aucun type de logiciel. Nous faisons différents niveaux d’abstraction à l’intérieur du chemin de données. Ces types de solutions nous aident à améliorer considérablement les performances de notre appareil et prolongent également la durée de vie utile des appareils. L’un des exemples de solution basée sur la bande est le contrôleur de volume réseau total de la zone de stockage d’IBM.
Avec le mode symétrique, la fonction de virtualisation intercepte les requêtes des postes clients, interroge les serveurs de fichiers puis transmet les flux de données.
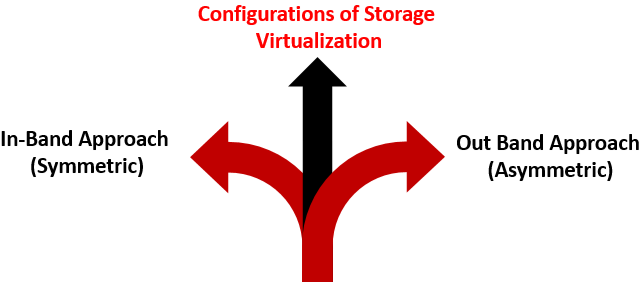
L’approche hors bande (asymétrique) : Dans cette approche, l’implémentation de l’environnement virtuel se fait en dehors du chemin de données vu que le flux de données et le flux de contrôle sont séparés, ce qui peut être réalisé en séparant nos métadonnées des données et en les plaçant à différents endroits. Ce type de virtualisation implique le transfert de toutes les tables vers un contrôleur de métadonnées qui contient tous les fichiers de métadonnées. En séparant les deux flux, nous obtenons l’utilisation de la bande passante complète offerte par le réseau de stockage.
La fonction de virtualisation, alors exclusivement embarquée dans le boîtier (appliance), se limite à la mise en relation des clients et serveurs. Les données circulent ensuite directement via le réseau.
Pour mieux comprendre, nous allons installer un logiciel gratuit qui offre des services de stockage et qui permet aussi le partage des fichiers et d’applications en ligne, ownCloud.
Owncloud nous permet de créer notre propre solution de stockage cloud.
Installation d’owncloud (macOS)
Installation sur macOS à l’aide du Docker
OwnCloud n’est pas officiellement pris en charge par macOS et ne propose pas de package pour cela, c’est pourquoi Docker, une solution de virtualisation basée sur des conteneurs vient à notre rescousse. Avec Docker vous exécutez essentiellement un mini-linux dans une petite machine virtuelle. Exactement ce dont nous avons besoin.
Alors c’est parti !
Prérequis : Installer Docker, Apache et MySql
Etape 1 :
- Installer Docker
Si vous ne l’avez pas déjà fait, téléchargez et installez docker. https://docs.docker.com/docker-for-mac/
Suivez simplement les instructions données. Vous pouvez vous arrêter après avoir terminé “Step 1”. Nous allons reprendre les choses à partir de là.
- Créer un fichier de composition Docker
Docker compose vous permet d’automatiser une configuration de docker plus complexe. Dans notre cas, nous avons besoin de deux images Docker (essentiellement deux petites machines) : une pour OwnCloud lui-même, une pour le serveur de base de données (MariaDB).
Pour créer le fichier, ouvrez d’abord le terminal, puis saisissez les commandes suivantes depuis un shell :
cd mkdir owncloud_docker cd owncloud_docker/ touch docker-compose.yml open docker-compose.yml
La dernière commande devrait ouvrir le fichier docker-compose.yml dans votre éditeur de texte. Mettez-y le contenu suivant :
# ownCloud with MariaDB/MySQL # version: '2' services: #OwnCloud machine owncloud: image: owncloud ports: - 8080:80 # CHange port from 8080 to any other port if you like. This is the port you will reach your server at. volumes: - ~/.owncloud_docker:/var/www/html # This makes sure your owncloud data is stored on your Mac. You can change the folder by replacing ~/.owncloud_docker with any other folder # Database server mysql: image: mariadb volumes: - ~/.mariadb_docker:/var/lib/mysql # This makes sure your database dat ais stored on your Mac. You can change the folder by replacing ~/.mariadb_docker with any other folder environment: MYSQL_ROOT_PASSWORD: example #You may change this
Assurez-vous que vous avez bien changé MYSQL_ROOT_PASSWORD (dans le cas d’un déploiement) et veuillez à changer de port si jamais un serveur fonctionne déjà sur le port 8080, vous pouvez laisser le reste tel quel si vous le souhaitez. Enregistrez le fichier, vous êtes prêt à continuer.
Etape 2 : Installer Apache
La bonne nouvelle c’est que Apache est déjà installé en natif sur OSX. Donc pour activer Apache, rien de plus simple, il faut ouvrir un terminal puis de demander son exécution :
esudo apachectl start
L’inconvéniant est que l’accès au répertoire par défaut de Apache n’est accessible qu’en tant que superutilisateur root, ce qui est gênant pour l’utlisation courante. L’idée serait de déplacer le répertoire DocumentRoot dans une zone où l’écriture par l’utilisateur courant est possible. On va donc ouvrir le fichier de configuration.
sudo nano /etc/apache2/httpd.conf
Chercher la ligne contenant la définition de DocumentRoot et remplacez par le répertoire qui vous parait bon, ici /Volumes/backup/www (sans le / à la fin !)
DocumentRoot "/Volumes/backup/www" <Directory "/Volumes/backup/www"> Options FollowSymLinks Multiviews MultiviewsMatch Any AllowOverride All Require all granted </Directory>
Une fois ces modifications faites, il faut redémarrer le serveur :
sudo apachectl restart
Etape 3 : Installer MySql
Pour installer MySQL vous pouvez récupérer le fichier pkg sur le site de MySQL directement : https://dev.mysql.com/downloads/mysql/
À titre personnel, je préfère MariaDB et pour l’installer il vous faut installer le gestionnaire de package Homebrew :
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Une fois Homebrew installé, on lance :
brew install mariadb
Une fois l’installation terminée, pour lancer le serveur il suffit d’exécuter
brew services start mariadb
Maintenant vous devriez pouvoir vous connecter à la base en utilisant :
mysql -u root
Etape 4 : Créez une base de données MySql pour Owncloud.
Une fois connecté au serveur de base de données, nous allons créer une base de données et lui donner le nom que nous voulons, dans mon cas j’utiliserai test.
CREATE DATABASE test;
À ce stade, nous allons créer un nom d’utilisateur et un mot de passe pour notre base de données. Dans ce cas, j’utiliserai testUser en tant qu’utilisateur et mdpUser comme mot de passe. N’oubliez pas que vous pouvez utiliser les valeurs souhaitées (et surtout pas celles indiquées ici) :
GRANT ALL ON test.* to 'testUser'@'localhost' IDENTIFIED BY 'mdpUser';
Attribuez immédiatement les opérations de privilèges de vidage en tapant la commande suivante:
FLUSH PRIVILEGES;
Enfin, quittez MySql en utilisant la commande:
exit
Installation et configuration de ownCloud :
Démarrer ownCloud
Ensuite, nous allons réellement démarrer le ou les serveurs.
Revenez à la fenêtre du terminal et tapez ce qui suit:
docker-compose up -d
Cette commande téléchargera les images requises (assurez-vous que vous êtes connecté à Internet) et démarrez le serveur.
Si tout fonctionne comme prévu, vous devrez pouvoir accéder à votre instance ownCloud à l’adresse http://localhost:8080. Place à l’installation !
Configurer ownCloud
Si tout s’est bien déroulé, vous devriez voir l’écran de configuration ci-dessous.
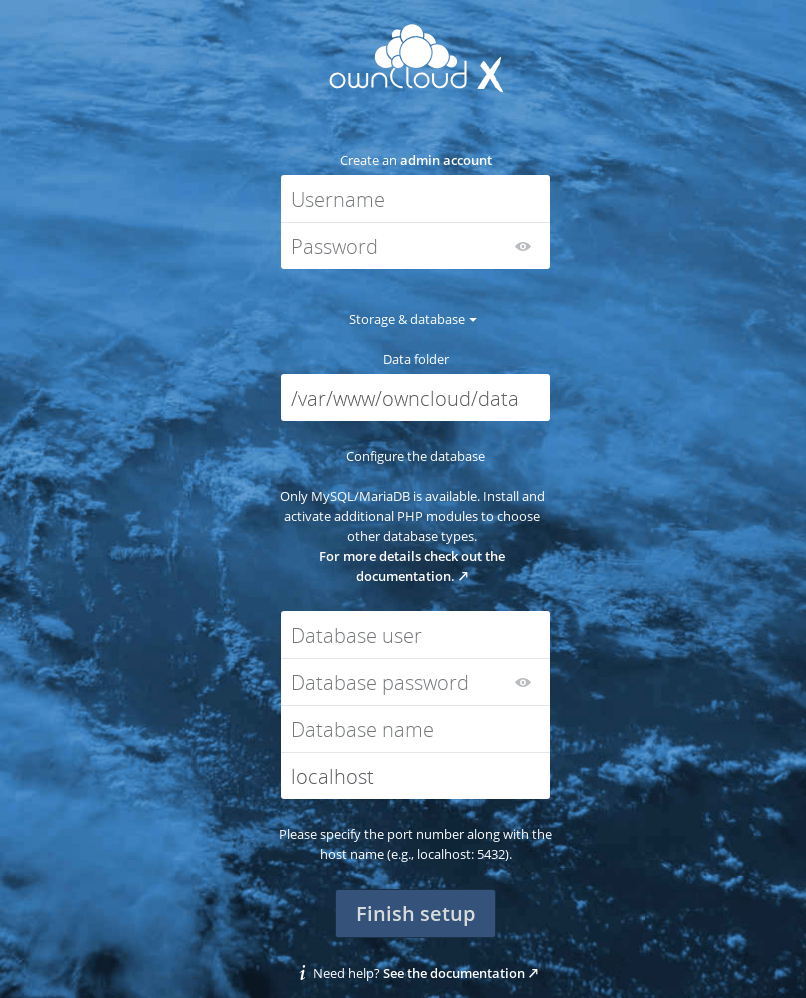
Vous pouvez choisir votre propre nom d’utilisateur et mot de passe administrateur. Cliquez ensuite sur Storage & database et entrez les paramètres suivants :
Database user: root
Database password: le MYSQL_ROOT_PASSWORD de l’étape 1 dans le fichier docker-compose.yml
Database name: owncloud
Database host: mysql
Cliquez sur Finish setup et attendez que le serveur soit configuré (cela peut prendre un certain temps…).
Voilà tout. Votre propre instance d’OwnCloud est opérationnelle. Tout ce que vous devez faire maintenant est vous assurer que vous pouvez y accéder depuis Internet (par exemple en utilisant des dyndns et un port forward) et installer les applications client OwnCloud sur vos appareils.
Liens utiles :
https://www.lemagit.fr/definition/Storage-Area-Network-SAN
https://owncloud.org/download/

Bonjour ! Je vous remercie pour cet article. C’est vrai que la virtualisation du stockage représente un pilier fondamental dans le processus de transformation digitale des entreprises, offrant une flexibilité et une efficacité inégalées dans la gestion des données. L’intégration de la virtualisation dans des infrastructures informatiques aident entreprises à optimiser l’utilisation des ressources, réduire les coûts et accroître la résilience de leurs systèmes. Dans le contexte du cloud computing, la virtualisation du stockage devient encore plus cruciale, permettant aux entreprises de déployer et de gérer leurs données de manière dynamique et évolutive. En libérant les données des contraintes matérielles, la virtualisation ouvre la voie à une agilité accrue, facilitant ainsi l’innovation et la mise sur le marché rapide de nouveaux produits et services. De plus, la virtualisation univirtual du stockage offre une gestion centralisée et simplifiée des données, ce qui simplifie les opérations de sauvegarde, de récupération et de migration. Cette consolidation des ressources améliore l’efficacité opérationnelle et permet aux équipes informatiques de se concentrer sur des tâches à plus forte valeur ajoutée. Alors, la virtualisation du stockage est un élément clé de la transformation digitale univirtual, permettant aux entreprises de tirer pleinement parti des avantages du cloud computing tout en garantissant une gestion efficace et sécurisée de leurs données dans un environnement en constante évolution.