DECOUVRIR LE CODE SOURCE DU NOYAU LINUX
Le système d’exploitation Linux est constitué de plusieurs composants et chaque distribution Linux enrichit sa version du système en rajoutant tel ou tel module supplémentaire. Mais c’est le noyau de Linux, que partage toutes les distributions, qui place Linux à part. Dans le foisonnement des différentes distributions, le noyau Linux reste le socle qui garantit les qualités intrinsèques de Linux. Songez que c’est quasiment le même noyau qui tourne sur des plateformes matérielles aussi différentes qu’un serveur, un ordinateur de bureau ou un téléphone mobile (alors que Windows NT devient Windows CE et MAC OSX devient iOS). C’est sa conception, son architecture et sa capacité d’abstraction à tous les niveaux qui rendent le noyau Linux capable de s’adapter à des matériels aussi divers et lui confèrent une telle versatilité.
Le noyau Linux est un programme informatique d’une extraordinaire complexité et évolue de plus sans cesse. En septembre 2018, le depot Git qui contient son code source sur kernel.org comptait 25 millions de ligne de code, écrites par 19 000 contributeurs au travers de 780 000 commits. C’est l’une des oeuvres les plus abouties du génie humain. Un homme seul, Linus Torvalds, en a été à l’origine, mais il a été rejoint par une très large communauté. Notons tout de même que Linus est encore l’auteur chaque année de 2 à 3% des commits…
Nous nous proposons ici rien de moins que d’aller regarder le noyau Linux de près, même de très près en allant découvrir son code source. Nous allons bien sûr survoler ce code à haute altitude mais d’assez près néanmoins pour avoir une idée de la conception de cet ouvrage. Nous ferons même un piqué sur le code source du processus Init qui est le surveillant général du système, qui lance tous les services au démarrage et éteint la lumière en partant à l’arrêt du système.
Ceci sera d’autant plus facile que le code est open source et à la disposition de tous (à condition de respecter les licences open source ad hoc bien sûr).
Contenu d’une distribution Linux
Le noyau seul est inexploitable, tel le moteur nu d’une voiture de course. Il faut quelques composants en plus pour arriver à un système d’exploitation capable de rendre des services à des utilisateurs ou réaliser des tâches concrètes.
Le coeur du noyau (le noyau du noyau) est monolithique. C’est un programme compact qui a son propre espace d’adressage. On peut lui adjoindre des modules ensuite qui vont réaliser d’autres fonctions en s’appuyant sur les services fournis par le noyau (les appels systèmes). Chaque version de Linux peut rajouter ses propres modules. Chaque nouveau service sera fourni par un ou plusieurs démons (des processus lancés par Init, le père de tous le processus, au démarrage du système) qui s’exécuteront en cachette, sans interaction directe avec l’utilisateur, en charge de réaliser le service.
Le shell, autre composant très important, est le programme qui gère les instructions tapées par l’utilisateur sur la ligne de commande, ou celles contenues dans des fichiers de commandes (scripts). Il existe plusieurs types de shells (Le shell bash -Bourne Again Shell- est très courant). Au passage notons que les noms de commandes, fichiers, et services Unix regorgent de jeux de mots plus ou moins approximatifs et de séquelles historiques dont les initiés se régalent. Le shell offre des dizaines de commandes pour interagir avec le noyau et commencer à faire un réel travail. Les puristes veulent s’en tenir là. Les autres exigent des interfaces graphiques.
Le X Window Server (très souvent Xorg) gère l’interface graphique et exécute les instructions données (en local où à distance) ayant un effet graphique.
Le Window Manager (par exemple Metacity, KWin, Xfwm, Compiz) et le Desxtop Environment (par exemple GNOME, KDE, Xfce) gèrent les échanges avec l’utilisateur au moyen d’interfaces graphiques.
Pour connaitre son noyau et sa distribution
cat /proc/version
Pour connaitre sa version du shell
echo $0
Pour connaitre sa version X Window Server
ps -e | grep X
Pour connaitre sa version X Window Manager
wmctrl -m
Pour connaitre sa version de Desktop Environment
ls /usr/bin/*session
Faire connaissance avec le noyau linux
Linus Torvals a commencé à travailler sur le noyau Linux en 1991 en s’inspirant de Minix développé par Andrew Tanenbaum.
Le noyau en est à la version 4.20.
La version 1.0 a été publiée en 1994, la version 2.0 en 1996, la version 2.4 en 2001, la version 3.11 en 2013, la version 4.15 en janvier 2018 (tentant de trouver une parade aux bugs Spectre et Meltdown des processeurs Intel).
Il s’agit de versions stables. Les versions intermédiaires sont affectées du suffixe rc (release cycle).
La taille du code n’a cessé de croître au fil des versions comme on peut le voir ci-après.
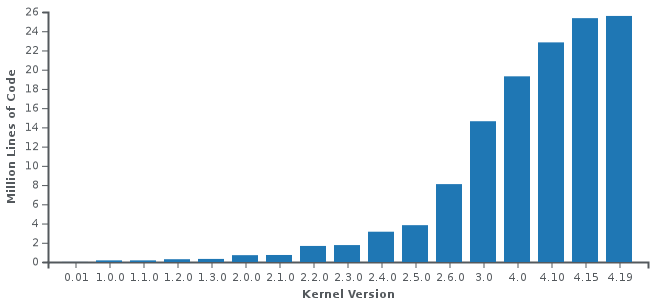
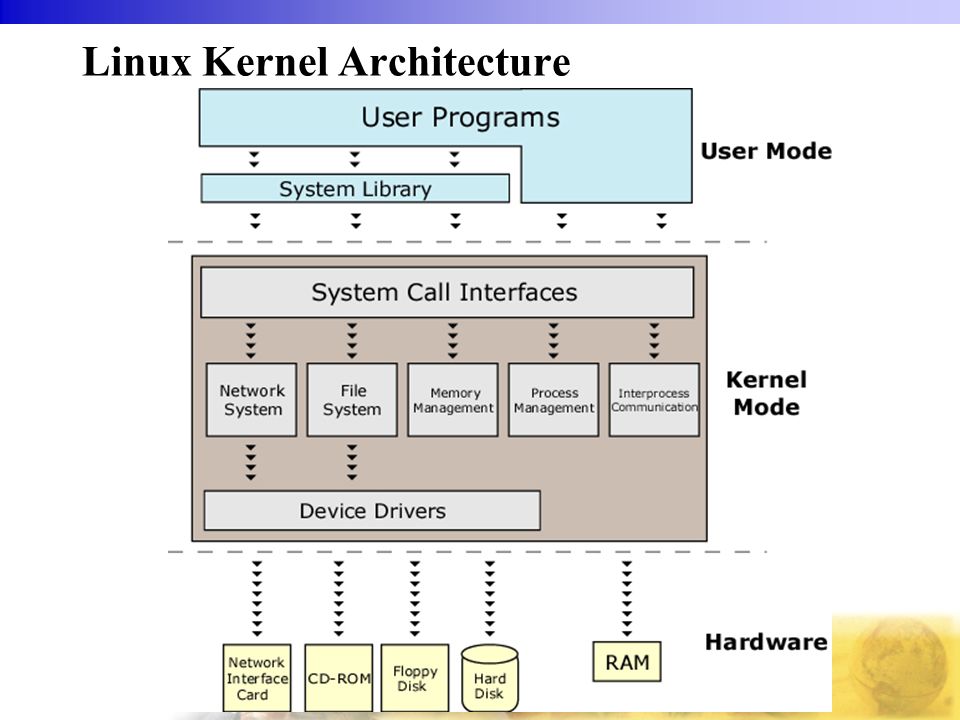
Il y a plusieurs façons de visualiser l’architecture du noyau Linux.
Voici ci-dessous une vision fonctionnelle, où l’accent est mis sur la mission du noyau de fournir des API aux programmes utilisateurs en fournissant une abstraction de tous les objets sous-jacents (matériels, mémoire, fichiers, processus..).
Les sources du noyau Linux figurent en principe dans chaque distribution dans le catalogue /usr/src mais sont souvent largement incomplètes.
Pour avoir le code source du noyau qui tourne sur votre machine, il faut faire la commande:
apt-get source linux
Pour avoir les versions les plus récentes il faut aller sur le site de référence www.kernel.org.
Sur ce site, on voit qu’en février 2019, la dernière version stable est la version 4.20.13 alors que les développeurs viennent de mettre en ligne la version 5.0rc8.
Le développement du noyau se fait sur un dépot git particulier (ce n’est pas Github) https://git.kernel.org/.
Pour télécharger le code source du noyau, le plus simple est de faire un clone git de la dernière version stable grâce à la commande:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
et pour avoir la dernière version de travail, faire un clone de la branche de Linus Torvalds himself avec la commande:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
Explorer le code source
Le code source contient (en sept 2018) plus de 61 000 fichiers.
Voici les principaux catalogues du premier niveau de l’arborescence:
Documentation/
Une documentation abondante est fournie mais sans vocation pédagogique. Cette doc entre tout de suite dans le dur.
Comme pour la plupart des projets open source, on ne dispose pas hélas de document de haut niveau décrivant l’architecture globale.
arch/
Ici figurent toutes les fonctions spécifiques aux différentes architectures (arm, x86, sparc, powerpc…).
drivers/
contient les codes de commande des périphériques
fs/
contient les codes propres aux différents systèmes de fichiers (ext2, ext4, fat, ntfs…)
include/
contient la majorité des fichiers .h utilisés dans tout le noyau
init/
contient le code en charge de la mise en route du système, juste après la phase de boot préliminaire
ipc/
contient le code en charge des communications entre processus
kernel/
attention il ne s’agit pas du coeur du noyau. C’est plutôt ici que sont rangés les sources qu’on n’a pas réussi à placer ailleurs
lib/
contient des fonctions et utilitaires utilisées un peu partout dans le noyau
mm/
contient les fonctions en charge de la gestion de la mémoire physique et de la mémoire virtuelle
net/
contient le code en charge des communications réseaux
scripts/
contient des scripts de service utiles pour compiler le noyau (qui n’iront pas dans l’image du noyau construite)
usr/
le code qui construit le premier systeme de fichier root
On est un peu pris de vertige à la vue de ces millers de fichiers.
Pour aider à la navigation dans le code source, on peut trouver quelques outils en ligne.
Le site de la société Bootlin est très utile pour cela https://bootlin.com/.
On peut explorer le code, cliquer sur le nom d’une fonction et repérer l’endroit où elle est déclarée ainsi que les fichiers où elle est utilisée, et cela pour toutes les versions du noyau.
Le code est très propre et de sévères régles de codage doivent être respectées par les contributeurs.
De nombreux pseudo-mots-clés sont définis en utilisant le mécanisme “attribute”.
Le mot clé __attribute__ (compris par le compilateur gcc) permet de donner des directives au compilateur et à l’éditeur de liens, par exemple pour libérer de la mémoire à bon escient, placer le code dans une zone mémoire particulière, etc..
Le pseudo mot-clé __section(S) par exemple est synonyme de __attribute__((__section__(#S))) qui indique à l’éditeur de liens de placer ce code dans une certaine section S.
Tous les pseudo-mots-clés sont définis dans le fichier include/linux/compiler_attributes.h.
Ce mécanisme offre de nombreuses possibilités, insoupçonnées pour le développeur C débutant.
Voici, pour les voir au moins une fois, toutes les options de __attribute__ :
aligned, alloc_size, noreturn, returns_twice, noinline, noclone, always_inline, flatten, pure, const, nothrow, sentinel, format, format_arg, no_instrument_function, no_split_stack, section, constructor, destructor, used, unused, deprecated, weak, malloc, alias, ifunc, warn_unused_result, nonnull, gnu_inline, externally_visible, hot, cold, artificial, error, warning.
Le code est incompréhensible sans la connaissance du mécanisme __atribute__.
L’abstraction est l’arme secrète du noyau Linux. Ainsi tout ce qui est spécifique à une architecture particulière figure dans le catalogue arch/ et l’ensemble de toutes les autres fonctions peuvent s’adresser à une même architecture abstraite.
Afin de décrire l’architecture de la machine sur laquelle il démarre, la plateforme matérielle est décrite au travers d’une structure de données particulière, le “Device Tree”, produit de l’Open Firmware Foundation. Un “Device Tree Blob” sera alors transmis par le bootloader au kernel au démarrage du système pour lui décrire la configuration matérielle de la machine.
Produire une image du noyau Linux
La production d’une image du noyau à partir du code source est une opération elle-même complexe.
Il faut spécifier l’architecture, les contours du noyau que l’on souhaite produire et une foule de paramètres de configuration pour tous les périphériques que l’on souhaite prendre en compte.
Toutes les options de configuration possibles auront été prévues par les développeurs dans des fichiers Kconfig particuliers, qui figurent dans la plupart des catalogues.
Il faut également indiquer la liste des modules dont des images seront produites à côté du noyau et qui pourront alors être chargés de façon dynamique.
Le fichier Makefile au sommet de l’arborescence est utilisé pour lancer ensuite la production des images et fera appel récursivement aux fichiers Makefile des niveaux inférieurs (plus de 500 Makefile au total).
Les fichiers Makefile sont parfois complétés par des fichiers Kbuild avec une syntaxe particulière.
Mettre à jour son noyau
Mettre à jour le noyau de son système Linux est une opération simple (pour les initiés..) mais longue et potentiellement dangereuse.
En voici les principales étapes:
- télecharger la dernière version du code source du noyau
- définir une configuration avec la comande
make menuconfig
- lancer la compilation avec simplement la commande
make
- attendre (un certain temps, jusqu’à 1 jour ou deux…)
- installer le noyau, en particulier modifier la configuration du bootloader, grâce au shell sbin/installkernel
- rebooter
Le processus Init
Le processus Init est le premier lancé à la mise en route du noyau et lance tous les autres processus en charge de la fourniture des différents services propres à chaque niveau de run (6 run levels possibles). Des fichiers de configurations spécifient les services associés à chaque niveau de run ainsi que le niveau de run souhaité au démarrage (un seul utilisateur, multi-utilisateurs, …).
Init est de plus en plus remplacé par un autre processus, nommé Systemd, mais le principe de fonctionnement est à peu près similaire.
Le code source des fonctions utilisés par ce processus figurent dans le catalogue init/.
Les fonctions principales sont dans le fichier main.c.
Ce fichier contient plus de 1100 lignes de code.
Les choses se passent à peu près ansi:
L’enchaînement au démarrage comprend l’appel au BIOS, puis au Bootloader (Grub le plus souvent), puis au lancement du noyau.
Cette étape, set-up part, est propre à chaque architecture et se termine par le lancement de la foncton start_kernel() qui figure dans init/main.c.
Cette fonction start_kernel() démarre une console pour échanger avec l’utilisateur, allume les interruptions et appelle la fonction rest_init(). C’est cette fonction qui va finalement créer un processus éxecutant le programme /etc/init.
Vincent Bonnevalle, Djamal Checkroun, Hugo Pompougnac, Julien Rolland, Slimane Siroukane
