Les services de Kubernetes ont déjà été vaguement traité dans un article précédent. L’objectif de cet article est d’obtenir un aperçu plus avancé de cette abstraction fournit par Kubernetes. Nous verrons l’intérêt de regrouper les Pods en Services pour accéder à votre application. Nous discuterons du rôle de kube-proxy et enfin nous explorerons les différentes méthodes de résolutions de services.
Les services : une couche d’abstraction indispensable
Prenons un exemple : pour accéder à une application, le développeur doit accéder au Pod qui contient son application. Or par définition, un Pod est un objet éphémère qui peut très bien mourir subitement par exemple. C’est pourquoi l’adresse IP d’un Pod ne peut pas être fixé.
Mettons-nous dans la situation où un développeur accède directement à ses Pods à l’aide des adresses IP. Comme dans le schéma suivant :

Que se passe-t-il si un des Pods devait mourir de manière abrupt ? Le système de résilience aux pannes de Kubernetes activerait probablement la création d’une réplication. Ainsi il faudrait que l’utilisateur puisse à nouveau accéder au Pod, mais ce Pod a une nouvelle adresse IP.
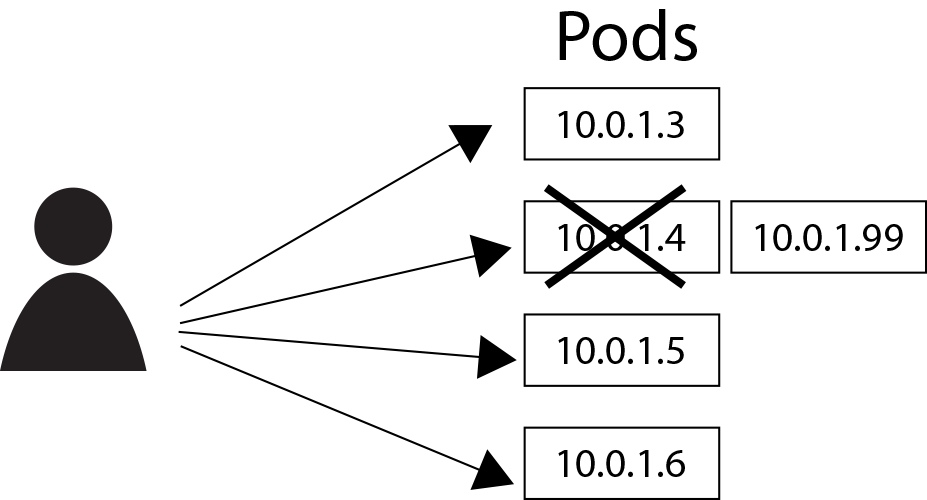
Un autre scénario voudrait par exemple qu’on ait à gérer du côté du backend une application de calcul sur des images. Lors d’une mise à l’échelle le développeur convient d’utiliser 4 réplications de l’instance de l’application. Le client (dans le côté du frontend) ne devrait pas se soucier de savoir à quelle instance parler, il faut simplement qu’il en sélectionne une disponible. Ainsi il est nécessaire d’introduire une forme d’abstraction pour résoudre ce problème.
C’est ici que l’on introduit les services. Les services permettent de regrouper des Pods et possède des politiques d’accès propres. Les regroupements de Pods pour un service se font à l’aide de Labels et de Labels selectors.
Regrouper les Pods en Services
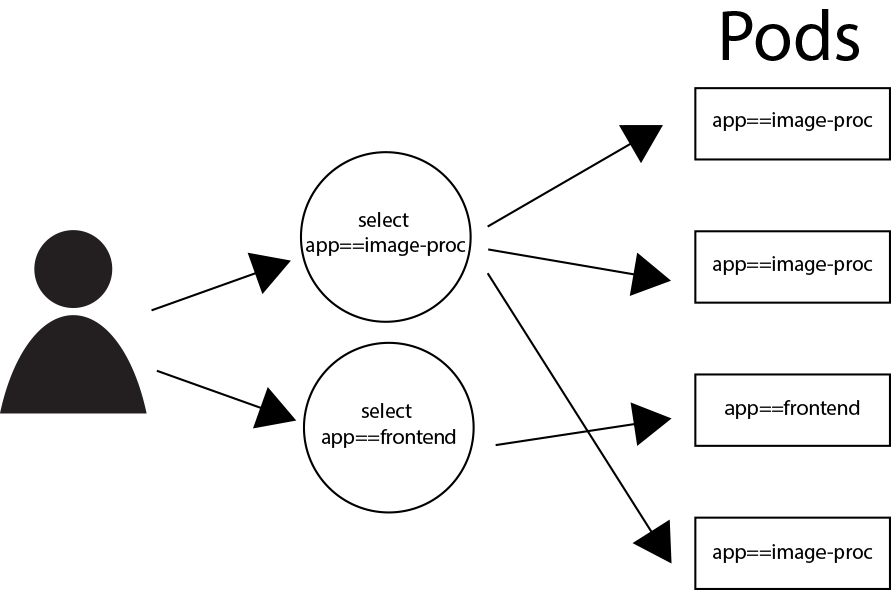
Dans le schéma ci-dessus, nous voyons de selectors qui permet de composer deux groupes logiques de Pods. Un groupe de 3 Pods contenant nos réplications d’Image Processing et un groupe d’un seul Pod contenant notre Frontend. Dès lors, nous pouvons assigner à ces groupes logiques des Noms de Services. Ces identifiants permettent de désigner des services qui ont leur propre VIPs (Virtual IPs). Le développeur n’aura plus qu’à désigner ces adresses IP virtuelles pour accéder à ses applications sans se soucier de la volatilité de ces dernières.

Définir un service Kubernetes
Nous pouvons définir des services très facilement à partir d’un label selector et en définissant le protocole et les ports d’entrée et de sortie de la manière suivante (nous reprenons notre exemple d’Image Processing) :
kind: Service
apiVersion: v1
metadata:
name: image-proc-svc
spec:
selector:
app: image-proc
ports:
- protocol: TCP
port: 80
targetPort: 2238À ce stade l’utilisateur peut accéder à notre service de calcul d’image à l’aide de la VIP : 172.12.0.1 qui sera statique. Le traffic sera alors redirigé sur un Pod disponible. Remarquez que lorsqu’un service représente un ou plusieurs Pods, nous pouvons les appeler Service endpoint. Concrètement le service image-proc-svc possède 3 endpoints qui sont accessibles au port 2238
Les Services sans utiliser de sélecteurs
Même si les services fonctionnent généralement avec les Pods, il peut être envisageable de vouloir utiliser d’autres types de backend. Par exemple si vous ne voulez pas utiliser votre base de données en production mais plutôt celle de test ou bien tout simplement utiliser une application qui n’est pas dans votre cluster Kubernetes. Ainsi nous définissons notre service suivant sans utiliser de sélecteurs :
kind: Service
apiVersion: v1
metadata:
name: db-svc
spec:
ports:
- protocol: TCP
port: 80
targetPort: 2238Cependant, comme ce service ne possède pas de sélecteurs, il n’y aura pas de Endpoints créés. Il faudra alors définir votre propre Endpoint :
kind: Endpoints
apiVersion: v1
metadata:
name: db-svc
subsets:
- addresses:
- ip: 1.2.3.4
ports:
- port: 2238Le rôle de kube-proxy avec les services
Pour chaque nœud, il y a un deamon appelé kube-proxy. Ce deamon communique entre autre avec le Master Kubernetes pour ajouter ou supprimer un service et ses Endpoints. Ainsi pour chaque service, kube-proxy va configurer ses règles iptables pour rediriger son trafic vers ses Endpoints. Lorsqu’un service est supprimé, kube-proxy mettra à jour son iptables.
Deux méthodes de résolution de services
Les services représentent le mode de communication le plus élémentaire dans Kubernetes. Il est primordiale de pouvoir les retrouver lors de l’exécution de notre cluster. Pour résoudre ce problème nous avons deux méthodes : les variables d’environnement et le DNS.
Les variables d’environnements
Lorsqu’un Pod démarre, kubelet va copier dans ce dernier l’ensemble des variables d’environnements associées aux services actifs. Attention cette méthode requiert que vous ordonniez correctement le lancement des Pods et des services entre eux, au risque d’avoir un Pod avec un ensemble de variables d’environnement périmé par rapport aux services ciblés.
Le DNS de Kubernetes
Kubernets propose un service de résolution de nom de domaine (et donc de services) : Un DNS. Ainsi il est possible d’accéder à un service seulement à partir de son nom.
Il s’agit de la méthode la plus recommandée, de part le fait que le problème d’ordonnancement des variables d’environnement est résolu et aussi à cause de sa flexibilité.
Conclusion
L’utilisation de la couche d’abstraction que représentent les services est un élément essentiel dans la communication de Kubernetes. Vous avez maintenant un légère idée de l’implication de kube-proxy dans le fonctionnement des services ainsi qu’un aperçu des méthodes de résolution de services.
Mohammed Ansari, Elhadj Amadou Diallo, Samy Metadjer, Cheikh Sall
