La sécurité des systèmes qu’on utilise dans notre quotidien est une affaire primordiale. Les systèmes distribués, les systèmes d’exploitation, les objets connectés qui portent tous des informations personnelles et professionnelles, doivent assurer un niveau de sécurité assez solide et être non vulnérables.
Dans le domaine de la sécurisation, on parle de deux types de propriétés.
- d’un côté les propriétés de «liveness» ou les propriétés de vivacité qui définissent l’ensemble des tâches et processus que nous sommes autorisés à faire dans un système (en d’autres termes, les fonctionnalités du système).
- d’un autre côté, il y les propriétés de «safety» ou les propriétés de sûreté et qui définissent tout ce que nous ne sommes pas autorisés à faire dans les systèmes.
Par conséquent, sécuriser un système d’exploitation revient à lister les propriétés «safety» et s’assurer qu’il est bien impossible de réaliser une action interdite.
La cryptographie est l’une des techniques qui est très souvent employée, quand nous souhaitons parler de sécurité.
Elle présente les outils nécessaires, les algorithmes efficaces et la discipline incluant les principes, moyens et méthodes de transformation des données, dans le but de cacher leur contenu, d’empêcher que leur modification passe inaperçue et/ou d’empêcher leur utilisation non autorisée ainsi pour prévoir une attaque et construire les éléments qui résistent contre ces attaques.
Nous nous intéressons alors à l’application de la cryptographie dans le cadre l’anonymisation et la pseudonymisation.
Leur importance
Ces concepts deviennent de plus en plus critiques dans l’aire du monde numérique et de la virtualisation.
Et à fin de répondre aux exigences fixées par le Règlement Général de Protection des Données (RGPD), il est nécessaire de sécuriser techniquement les données personnelles. Ainsi, outre que la minimisation des données, deux grandes techniques de sécurisation sont disponibles: l’anonymisation et la pseudonymisation des données. Ce sont deux techniques dont le RGPD encourage fortement l’utilisation.
Elles peuvent avoir une distribution statistique qui leur est appliquée, garantissant que les remplacements ont une valeur statistique similaire aux données d’origine rendant ainsi toute ré-identification plus difficile.
Qu’est ce qu’est l’anonymisation?
L’anonymisation est une technique permettant d’empêcher de manière irréversible l’identification d’une donnée. Plus spécifiquement, elle consiste à changer le contenu ou la structure même des données, de sorte que toutes les informations pouvant mener à l’identification d’une personne soient supprimées ou modifiées.
https://fr.wikipedia.org/wiki/Anonymisation
Anonymiser une donnée suppose donc la suppression de l’identité de la personne à qui revient cette donnée. Par conséquent il est impossible de ré-identifier le propriétaire de la donnée.
Cette caractéristique rend l’anonymisation des données particulièrement adaptée aux situations non opérationnelles, comme le développement et la mise à l’essai: les utilisateurs finaux n’ayant pas besoin de voir les valeurs d’origine.
Méthodes de l’anonymisation
La randomisation :
Cette méthode consiste à brouiller la relation entre les données recensées et la personne physique. Le lien entre les données d’origine et celles obtenues est complètement brisés.
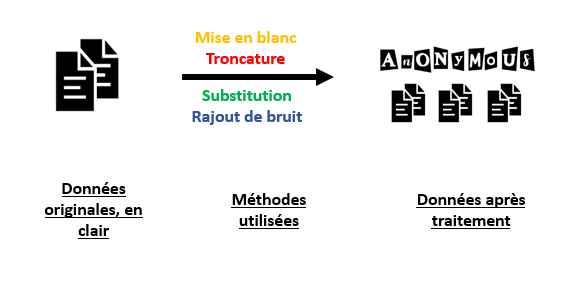
Exemple d’application de la technique de substitution :
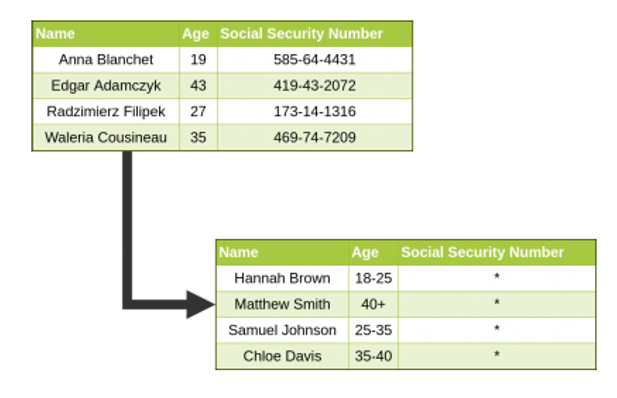
Dans cet exemple, il y a recours à la méthode de substitution :
- Le nom est remplacé par un autre nom aléatoire.
- L’âge est devenu radicalement inconnu et remplacé par simplement un intervalle qui ne nuit pas à la pertinence des données et n’affecte pas le résultat des études scientifiques appliquées à ces données.
- Le numéro de sécurité sociale est supprimé, de façon à ne pas reconnaître une personne à partir de son numéro attribué.
La généralisation :
Généraliser signifie enlever un degré de précision à certains champs. Le principe se base sur la dilution de la donnée ou sa généralisation en modifiant sa précision, son échelle, sa grandeur..
Le k-anonymat est alors utilisé. Il s’agit de :
- Déterminer les ensembles d’attributs qui peuvent être utilisés pour croiser les données anonymes avec des données identifiantes. (Par exemple on peut reconnaître une personne à partir de seulement son adresse et de son emploi). Ce sont les “quasi-identifiant”.
- Réduire le niveau de détails des données de telle sorte qu’il y a au moins k n-uplets différents qui ont la même valeur de quasi-identifiant, une fois celui-ci généralisé. C’est le fait de créer des classes d’équivalences.
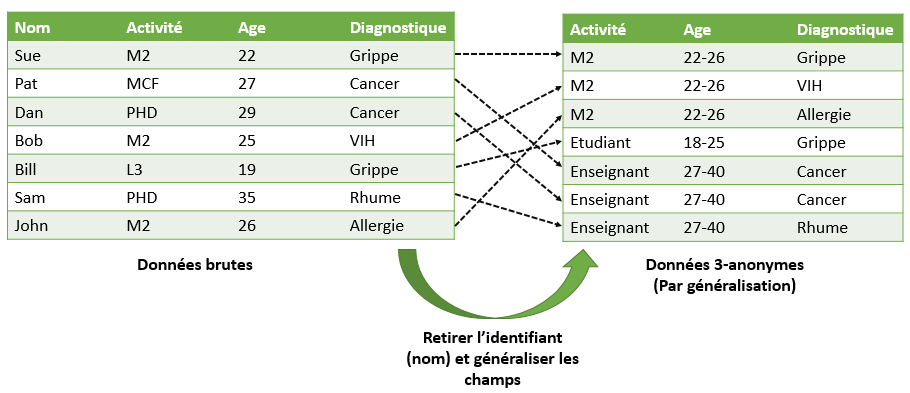
Dans cet exemple il y a recours à la suppression du champs identifiant principal qui est “nom” e il y a généralisation des champs activité et âge d’une base de données médicales sur des étudiants et enseignants d’une université. Les étudiants sont identifiés par leur niveau d’étude (L3, M1, M2..) qui se généralise en “étudiant”, et les enseignants par leur position académique (doctorant, maître de conférences …), qui se généralise en “enseignant”.
Nous traçons dans cette figure l’origine de chaque n-uplet flouté.
Qu’est ce qu’est la pseudonymisation ?
La pseudonymisation est un processus dans lequel les identifiants personnels sont remplacés par des pseudonymes. C’est une manière d’obtenir une liaison très forte entre l’origine de la donnée et son pseudonyme associé. En d’autres termes la pseudonymisation permet toujours d’identifier un individu grâce à ses données personnelles car elle consiste simplement à remplacer un attribut par un autre au sein d’un enregistrement.
Tout en protégeant l’anonymat de la personne concernée, les données pseudonomisées sont toujours considérées comme des données personnelles du fait qu’elles peuvent potentiellement être inversées dans certains cas.
La pseudonynimisation doit exécuter des algorithmes complexes qui rendent la ré-identification aussi difficile que possible.
C’est est un processus par lequel les données perdent leur caractère nominatif: elle permet donc de toujours identifier une personne physique grâce à ses données personnelles, car elle consiste tout simplement à remplacer un caractère par un autre dans le cadre d’un enregistrement et cela sans avoir recours à des informations supplémentaires. Les données ne sont donc pas vraiment anonymes sans être identifiables.
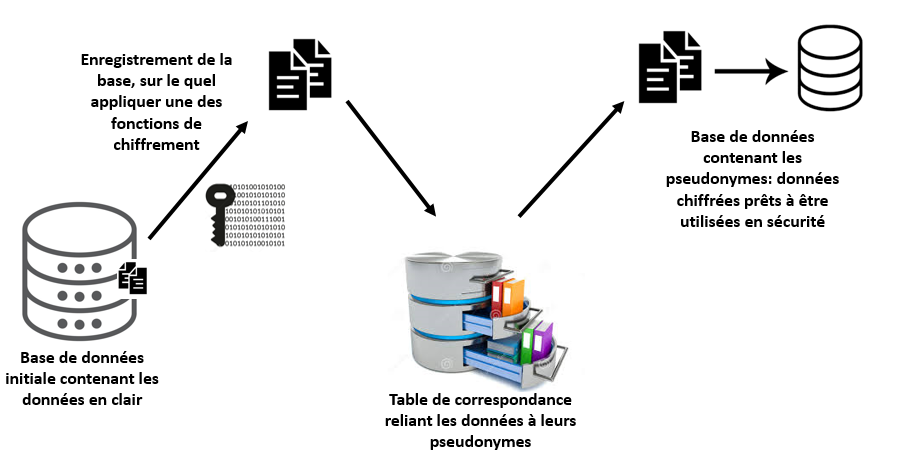
Il est important de noter que la table de correspondance doit être conservée séparément et dans des conditions particulières. On en a recours, que dans le cas où n veut relier les données obtenus avec les données de départ ce qui extrêmement rare.
Ces tables doivent être hautement sécurisées avec un contrôle strict de l’accès aux données sensibles.
Techniques de pseudonymisation
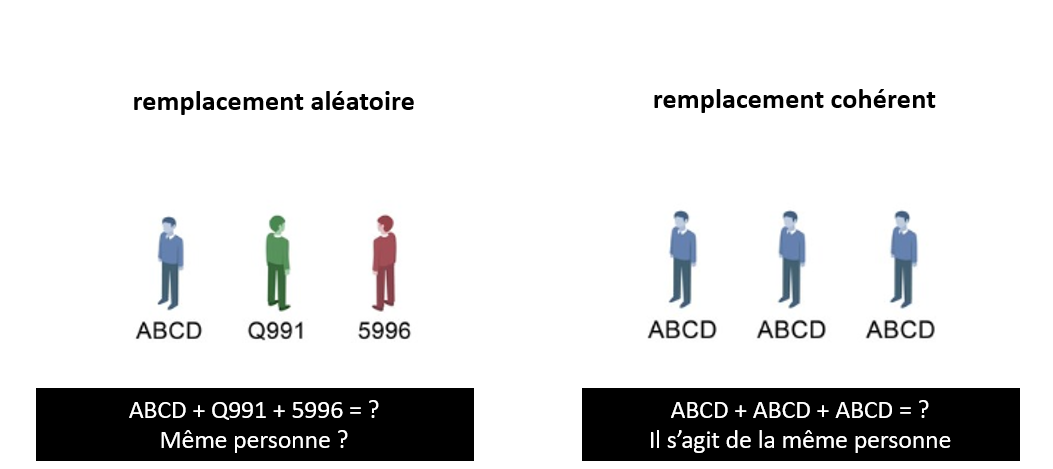
Il existe deux types de techniques de pseudonynimisation : le remplacement aléatoire et le remplacement cohérent.
- Le remplacement aléatoire: Mr. John Smith souhaite utiliser cette technique de pseudonynimisation. Un pseudonyme lui sera attribué. Mais si jamais il l’oublie, une prochaine fois, un autre pseudonyme aléatoire lui sera attribué.
- Par contre dans le remplacement cohérent: Mr. John Smith aura toujours le même pseudonyme, permettant ainsi d’analyser ce client dans le temps mais sans révéler sa véritable identité.
Outils utilisées pour la pseudonymisation
Nous citons maintenant les méthodes utilisées pour la Pseudonymisation.
Principalement, il s’agit de méthodes cryptographiques pour le chiffrement des enregistrements des personnes. Le choix de la méthodes revient au contexte et au degré de sécurité qu’on souhaite obtenir. Il existe de nombreuses techniques et elles offrent chacune un degré de sécurité, mais il est à noter que les erreurs sont aussi nombreuses lors de leurs mises en oeuvre.
- Système cryptographique à clé secrète :
Dans le cas d’un système cryptographique à clé secrète, le processus de ré-identification des personnes est simple pour le détenteur de la clé secrète. Ceci est fait par un décryptage des messages puisque les données à caractère personnel sont disponibles. En effet, dans les systèmes à clé secrète, il suffit de connaître la clé, pour obtenir une série de transformations applicables aux textes en bruts et aux textes chiffrés pour pouvoir casser le système. - Fonction de hachage :
La caractéristique principale de la fonction de hachage est qu’elle renvoie un résultat de taille fixe, quelle que soit la taille de l’entrée donnée. Le risque avec cette technique consiste au fait de trouver l’intervalle dans lequel se situent les valeurs des résultats. Afin de réduire ce risque, la fonction de hachage avec salage où une valeur aléatoire, appelée « sel », est concaténée à l’entrée de la fonction permet de réduire la probabilité de reconstituer cette dernière.
Cela réduit d’une façon considérable l’hypothèse de retrouver la valeur d’entrée. - Fonction de hachage par clé, avec clé enregistrée :
Il s’agit d’une fonction de hachage particulière qui utilise une clé secrète comme une autre entrée. Le détenteur de la clé peut encore ré-exécuter la fonction sur l’attribut en se servant de la clé secrète, mais pour un simple attaquant qui ne connaît pas la clé secrète cela est extrêmement difficile puisqu’en se basant sur la brute-force cela pourrait lui prendre des siècles. - Chiffrement déterministe ou fonction de hachage par clé avec suppression de la clé :
Cette technique consiste à sélectionner un nombre aléatoire comme pseudonyme pour chaque attribut de la base de données et à supprimer ensuite la table de correspondances. Cette technique est utilisée dans le remplacement aléatoire lors de la pseudonynimisation. En présence d’un algorithme puissant, il est très difficile pour un attaquant de casser le système même en présence d’une puissance de calcul élevée puisque la clé utilisée pour chaque pseudonyme a été supprimée.
Le choix de la technique à utiliser diffère d’un système à un autre et dépend du degré de sécurité souhaité et de l’application des données cryptées.
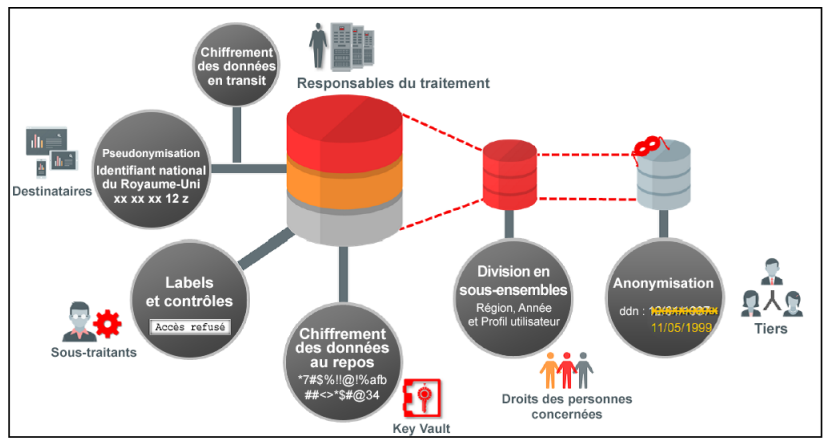
Exemple d’utilisation de l’anonymisation et de la pseudonymisation dans les contrôles préventifs de sécurité Oracle Database