Cet article sera une évolution de l’exemple WordCount qu’on a vu précédemment dans l’article Hadoop installation sous Windows, où on s’intéresse plutôt au calcul du nombre d’occurence d’un mot spécifique dans un ensemble de textes.
On commence par créer un projet Maven dans IntelliJ IDEA ou Eclipse IDEA, en définissant les valeurs suivantes pour le projet :
GroupID: hadoop.mapreduceArtifactID: wordcountmulinputVersion: 1
Ensuite, on ouvre le fichier pom.xml, et on ajoute les dépendances suivantes pour Hadoop, HDFS et Map Reduce:
<groupId>hadoop.mapreduce</groupId>
<artifactId>wordcountmulinput</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8.0_241</version>
<scope>system</scope>
<systemPath>C:/Java/jdk1.8.0_241/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.8.0</version>
</dependency>
</dependencies>
On crée la classe TokenizerMapperMultiInput sous le package hadoop.mapreduce.wordcount contenant le code suivant:
package hadoop.mapreduce.wordcountmultiinput;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class TokenizerMapperMultiInput
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper.Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
// Count a specific word
if(value.toString().compareTo("Hadoop!")==0)
{context.write(word, one);}
}
}
}
La classe TokenizerMapperMuliInput implémente la classe org.apache.hadoop.mapreduce.Mapper de Hadoop que l’on paramètre avec le type de la clé d’entrée (Object), le type de la valeur d’entrée (Text), le type de la clé des sorties intermédiaires (Text) et enfin le type de la valeur des sorties intermédiaires ( IntWritable). Pour écrire le code correspondant à l’opération Map, nous avons utilisons ici les types InitWritable et Text. Cette fonction commence par déclarer un itérateur de type StringTokenizer qui va itérer sur les valeurs d’entrée correspondants à la fichier input.txt. Ensuite, elle compare chaque mot lu par le mot qu’on a choisi. Si c’est la même, elle stocke le mot au niveau de la variable word suivi de la valeur 1, sinon elle passe au mot suivant.
Maintenant, On crée la classe IntSumReducerMultiInput sous le package hadoop.mapreduce.wordcount contenant le code suivant:
package hadoop.mapreduce.wordcountmultiinput;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IntSumReducerMultiInput
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
System.out.println("value: "+val.get());
sum += val.get();
}
System.out.println("--> Sum = "+sum);
result.set(sum);
context.write(key, result);
}
}
La classe IntSumReducerMultInput implémente la classe org.apache.hadoop.mapreduce.Reducer de Hadoop que l’on paramètre avec le type de la clé d’entrée (Text), le type de la valeur d’entrée (IntWritable), le type de la clé des sorties intermédiaires (Text) et enfin le type de la valeur des sorties intermédiaires ( IntWritable). Pour écrire le code correspondant à l’opération reduce, nous avons utilisons ici les types InitWritable et Text. La fonction reduce commence à parcourir la liste values qui est le résultat de la fonction map et elle compte le nombre d’occurrence de chaque mot dans le texte. A la fin, elle retourne le mot et son nombre d’occurrence. Mais il n’y a pas une difference entre cette classe et la classe IntSumReducer de l’exemple précédant WordCount.
Enfin, on crée la classe WordCountMultiInput sous le package hadoop.mapreduce.wordcount contenant le code suivant:
package hadoop.mapreduce.wordcountmultiinput;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMultiInput {
public static void main(String[] args) throws Exception {
// Create a job by providing the configuration and a text description of the task
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count multi-input");
// We specify the classes WordCount, Map, Combine and Reduce
job.setJarByClass(WordCountMultiInput.class);
job.setMapperClass(TokenizerMapperMultiInput.class);
job.setCombinerClass(IntSumReducerMultiInput.class);
job.setReducerClass(IntSumReducerMultiInput.class);
//We precise there are multi-path, not a single path
Path inputFilePath = new Path(args[0]+"/*/*");
Path outputFilePath = new Path(args[1]);
// Definition of the key / value types of our problem
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Definition of input and output files (here considered as arguments to be specified during execution)
//Using multiple input file
MultipleInputs.addInputPath(job, inputFilePath, TextInputFormat.class, TokenizerMapperMultiInput.class);
FileOutputFormat.setOutputPath(job, outputFilePath);
// Delete the output file if it already exists
FileSystem fs = FileSystem.newInstance(conf);
if (fs.exists(outputFilePath)) {
fs.delete(outputFilePath, true);
}
// run the job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
La classe WordCountMultiInput qui contient la fonction main du programme et qui va permettre de :
- Récupérer la configuration générale du cluster.
- Créer un job avec le nom word count multi-input.
- Préciser quelles sont les classes Map et Reduce du programme en utilisant les quatre setters setJarByClass(), setMapperClass(), setCombinerClass(), setReducerClass().
- Préciser les types de clés et de valeur correspondant à notre problème à l’aide de méthodes setOutputKeyClass(), setOutputValueClass().
- Indiquer où sont les données d’entrée et de sortie dans HDFS, et là où on a indiqué à MapReduce qu’il doit parcourir les différents répertoires de travail pour chercher l’occurrence de mot hadoop! au niveau de différentes fichiers à l’aide de l’objet inputFilePath et aussi l’objet MultipleInputs qui appelle la méthode addInputPath() qui prend en entrée quatre paramètres qui sont: job, inputFilePath, TextInputFormat, TokenizerMapperMultiInput.
- Supprimer le répertoire output d’une manière automatique s’il existe déjà.
- Lancer l’exécution de la tâche.
Tester Map Reduce en local
Dans le projet sur IntelliJ:
- On crée un répertoire input sous le répertoire resources de projet
- On génère 1000 mots avec de duplications en se servant de ce site https://www.randomlists.com/random-words.
- On crée un fichier de test: file.txt dans lequel on insère des mots
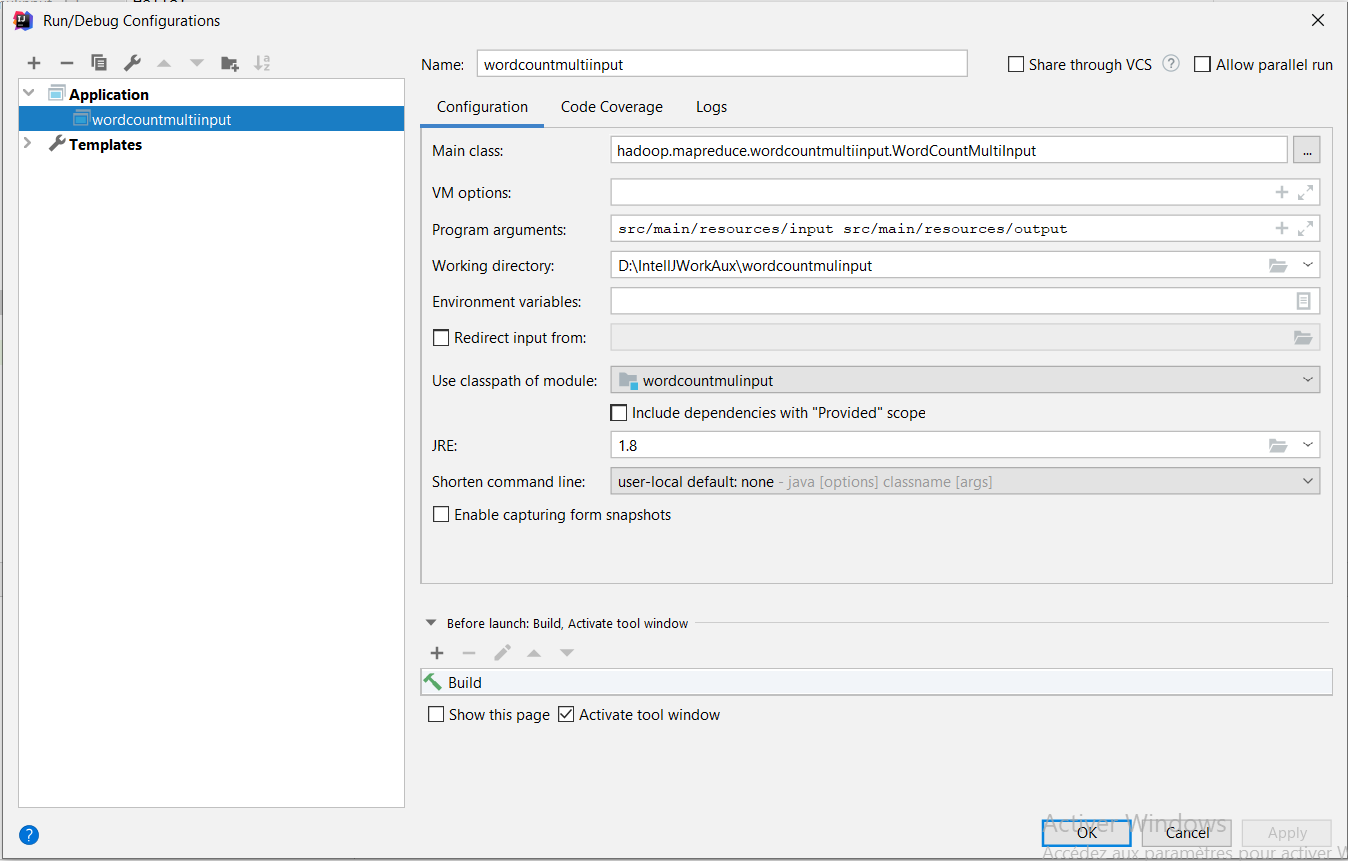
- On crée une configuration de type Application (Run->Edit Configurations…->+->Application).
- On définir comme Main Class: hadoop.mapreduce.wordcount.WordCount, et comme Program Arguments: src/main/resources/input/file.txt src/main/resources/output
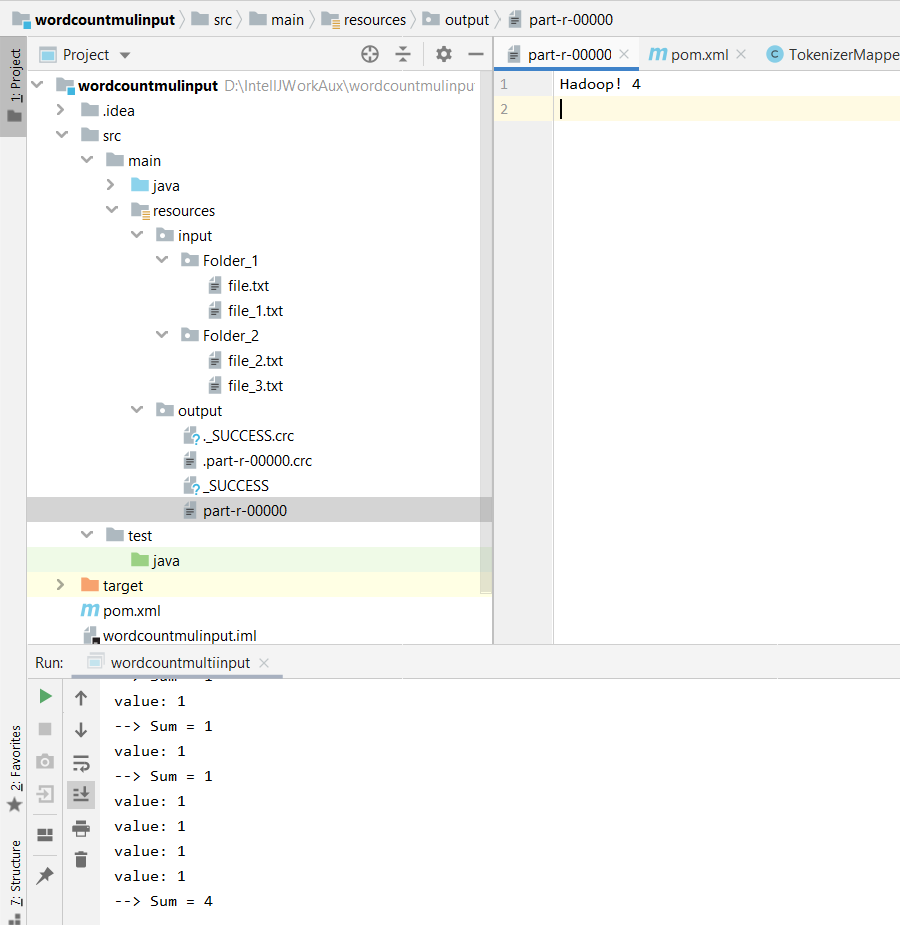
On lance le programme. Un répertoire output sera créé dans le répertoire resources, contenant notamment un fichier part-r-00000, dont le contenu devrait être le suivant:
Pour plus de détails sur le paradigme de programmation MapReduce: https://static.googleusercontent.com/media/research.google.com/fr//archive/mapreduce-osdi04.pdf
Pour tester le programme reportez-vous au projet GITLab du word count multi-input de Soufien Jabeur.
