Dans un précédent article, il était question d’introduire ce qu’étaient les namespaces Linux et de s’amuser à faire un petit peu de manipulation. Le terrain est désormais prêt pour aborder (à haut niveau) les liens entre les namespaces et Docker.
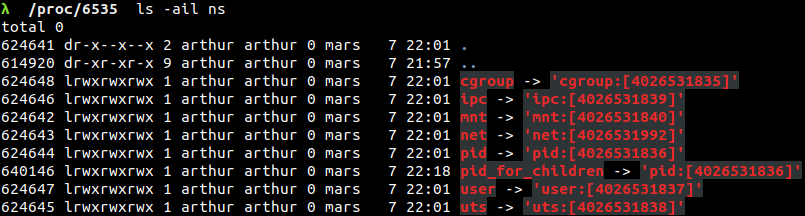
Il convient en premier lieu de spécifier la représentation des namespaces associés à un processus. C’est dans le sous-repertoire /proc/[PID]/ns que l’on peut trouver l’ensemble des liens symboliques les représentant. Chaque namespace possède donc un inode, ci-dessous l’exemple d’un processus lié à Firefox.
Il est temps de lancer un container Docker, sans s’attarder sur la manière de réaliser cette tâche (que vous pouvez retrouver dans l’article de Nassim), sachez juste que c’est un container basé sur une image contenant Python 3. À l’aide de la commande lsns, un listage des différents namespaces accessibles est fait. Accessibles puisque les informations sont extraites de /proc et peuvent donc ne pas être lues en fonction de l’utilisateur. Nous lançons de ce fait la commande en root côté hôte.
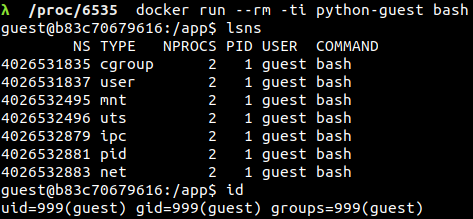
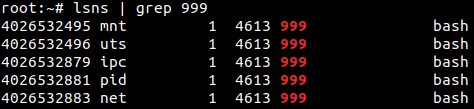
On se rend alors compte de deux choses au niveau des inodes. La première est qu’il n’y a pas de cgroup namespace depuis la vue de l’hôte. En effet, l’inode correspondant au type cgroup est le même que celui du namespace du processus lié à Firefox. C’est donc celui du namespace de l’initialisation du système qui est présent dans le container (et qui n’est d’ailleurs pas utilisé par Docker). La seconde est qu’il n’y a pas non plus d’user namespace, qui a encore une fois le même inode que celui du processus lié à Firefox. Cependant, l’user namespace est utilisé par Docker, il ne l’est juste pas par défaut. Pour se faire, il est nécessaire de spécifier au Docker daemon (lien vers article d’Akli) que l’on veut « remaper » un UID, via le flag –userns-remap="bob:bob" où Bob est un utilisateur existant.
On remarque ensuite que les namespaces sont associés au PID 1. C’est ici que le PID namespace joue un rôle, le PID à l’intérieur du container est différent de celui de l’hôte, qui est 4613.


On pourrait ensuite imaginer un autre container à l’intérieur de notre container ce qui donnerait trois processus différents de même PID (même si ce n’est pas recommandé).
L’un des namespaces les plus intéressant utilisé par Docker est sans doute celui du network, bien qu’un peu plus complexe. Souvenez vous de darlene, il était question d’utiliser une paire de veth pour la connecter à l’hôte. Le même principe est appliqué par Docker.
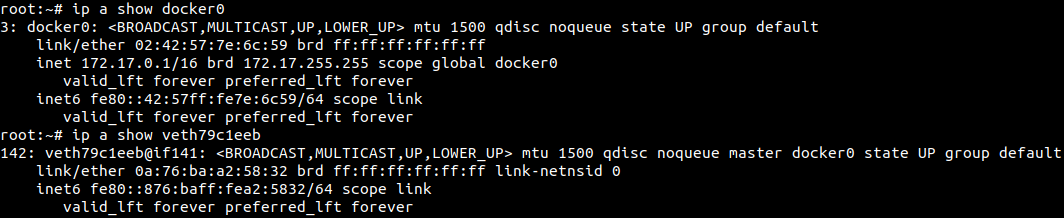

Dans la liste des interfaces réseau de l’hôte, on observe la présence de docker0. C’est un bridge à l’intérieur du kernel auquel tous les containers sont reliés, ils peuvent donc l’utiliser pour communiquer entre containers ou avec le monde extérieur via l’iptables NAT créées par Docker. On observe aussi, toujours chez l’hôte, une interface veth associé à l’interface d’index 141, c’est justement celle du container, qui est elle-même liée à l’interface d’index 142, le veth de l’hôte donc !
On peut de ce fait s’amuser à sniffer l’un des membres de la paire pour s’assurer du bon fonctionnement du réseau.
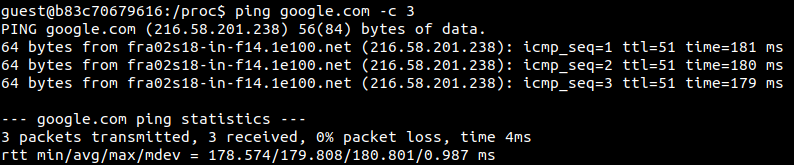
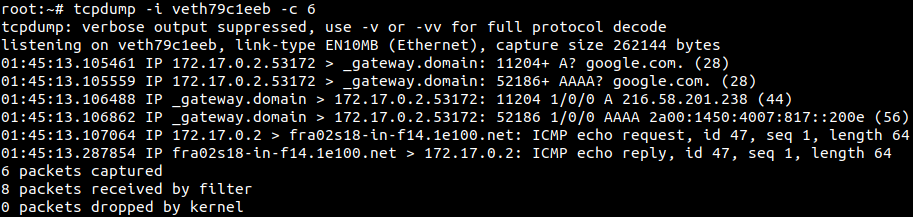
À noter la possibilité astucieuse de pouvoir «transporter» une interface réseau d’un container à un autre et une autre de pouvoir donner l’impression aux programmes à l’intérieur du container (d’un point de vue réseau) d’être l’hôte.
Le mount namespace est bien évidemment au coeur du container et permet entre autre d’avoir plusieurs répertoires comme /tmp, un dans chaque container. La mise en place du container se fait par un pivot_root. En listant les points de montage avec la commande mount à l’intérieur du container (non présenté ici pour des raisons évidentes de longueur), on observe qu’ils sont naturellement moins nombreux que ceux de l’hôte.
Pour finir, il faut bien comprendre que le terme de container n’est en fait qu’une manière de dire « ensemble de fonctionnalités assemblées et apportées par le kernel ». Afin de s’en rendre compte, nous allons utiliser la commande nsenter qui permet d’exécuter à l’intérieur d’un namespace un programme (un peu à la manière de docker exec). Ici, les namespaces seront ceux du container.

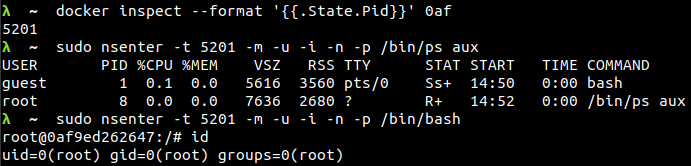
ps aux puis bash pour en voir les effets.On remarque tout de suite que l’utilisateur a l’intérieur du container est root ! C’est une fonctionnalité qui peut permettre par exemple de faire de la maintenance dans un container.
Nous l’avons donc vu, un container Docker n’est pas réellement une entité propre comme pourrait l’être une machine virtuelle, c’est avant tout un ensemble de fonctionnalités orchestrées par le kernel. Les namespaces en font partie, mais ils sont à ajouter aux cgroups, au copy-on-write, aux capabilities… Sans oublier que toute cette machinerie est possible grâce à libcontainer/runC et la spécification mise en place par l’OCI.
Quoi qu’il en soit, les namespaces restent une partie cruciale de l’architecture d’un container, aussi bien chez Docker qu’ailleurs.
