
Introduction
OCP est redhat “open source” une plate-forme de conteneur pour développer et héberger les applications de plusieurs sortent de modèles de cloud computing, comme :
- “Infrastructur as a Service”
- “Platform as a Service”
- “Software as a Service”

Ainsi Openshift offre des services de Platform as a Service, gérant les composantes d’infrastructures sous-jacentes et offrant aux devs un emplacement adéquat pour mieux développer leurs codes.

OpenShift est disponible en quatre versions :

- OpenShift Origin est la seule version open source pour la gestion des applications dans des conteneurs.
- OpenShift Online est la version qui permet d’exploiter les applications hébergées, en utilisant OpenShift Origin et aussi pour héberger d’autres applications.
- OpenShift Dedicated est géré dans des clusters privés comme AWS [Amazon Web Services] ou Google.
- enfin OpenShift Enterprise.
Dans cet article nous allons voir que la version :

OpenShift Origin est basé sur Docker (lire notre article Docker) et sur l’Orchestrateur Kubernetes (lire notre article Kubernetes). On recommande aussi la lecture de l’article sur OpenShift.
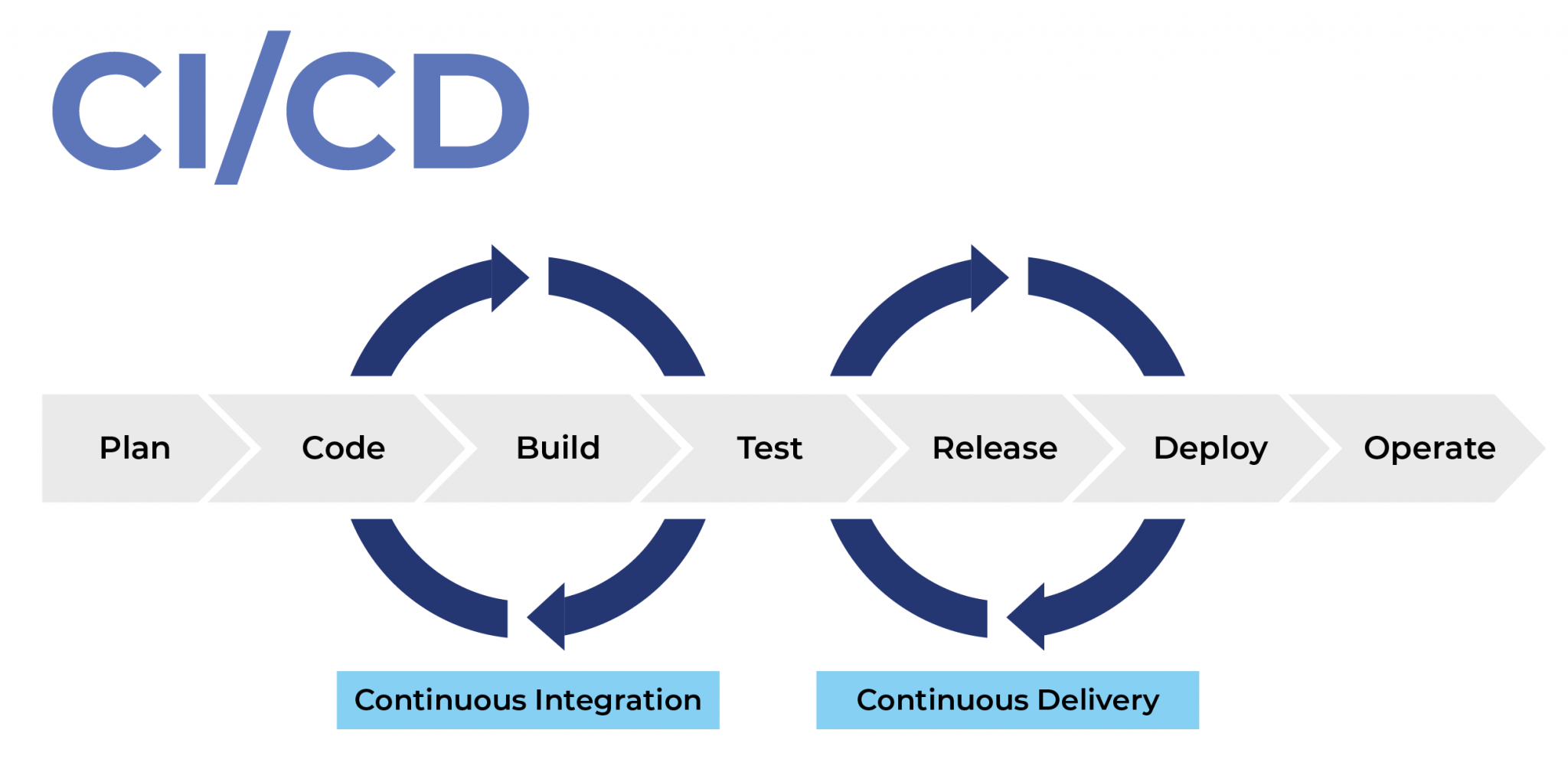
Avec l’ajout de deux approches CI/CD [ Continous Integration / Continous Delivery ] afin d’assurer une automatisation et une surveillance continue tout au long du cycle du vie d’une application.
Intégration continue
Pour mieux comprendre Continous Integration (Integration Continue), on a décidé de faire une petite analyse avant son déploiement et voir les problèmes qui ont permis d’adopter une telle approche.
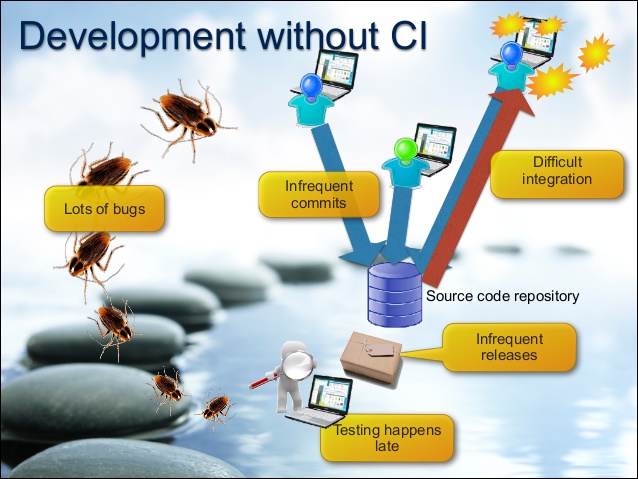
Commençons par l’ancienne approche, supposons qu’il s’agisse d’une société de type ESN qui dispose de 20 développeurs. Ces derniers vont devoir travailler ensemble en partageant leur code, mais le plus important c’est que chacun va se focaliser sur une tâche particulière. Prenons comme exemple deux devs qu’on nommera Alice et Bob, supposons qu’Alice va modifier le code en ajoutant une ligne d’instruction quant à Bob va supprimer cette ligne de code. Vous l’avez sans doute deviné, il y aura un problème au moment de la fusion des deux travaux c’est ce qu’on appel en anglais le Merge Hell, maintenant comment faire pour dépasser cet anomalie ?
Alice cette fois-ci va avoir une branche dans laquelle elle va commencer à écrire son code, une fois ceci terminé même si sa tâche n’est pas encore terminée, l’essentiel est que le code qu’elle a écrit est correct. Elle va soumettre push son code dans un serveur, Bob va télécharger pull ce code et il va commencer à le modifier dans une branche différente de celle d’Alice, disant qu’il va supprimer la ligne de ce code qui est inutile et il fait un push dans le même serveur.
Alice décide de faire des petites modifications en ajoutant quelques lignes dans son code, dans une telle situation elle va travailler sur la modification de Bob. On remarque, que les deux travaillent désormais sur la même chose au même temps, ainsi le conflit de fusion dont on a parle au-dessus quasi-négligeable.
Malheureusement, ce concept a créé un nouveau problème, n’oubliez pas que jusqu’à maintenant, nous avons pris l’exemple de deux devs qui vont travailler ensemble juste pour simplifier, mais en réalité y a plusieurs devs qui vont vérifier constamment le code dans le serveur, ce qui implique dans la majorité des cas la non compilation du code.
C’est la ou l’approche Integration Continue intervient afin de résoudre cette anomalie, le principe est le suivant nous allons équiper notre serveur d’une sorte de moteur d’automatisation qui va vérifier le code au fur et à mesure de sa création. Quand Alice crée son code, ce moteur va le compiler et le tester, si elle modifie le code n fois il va refaire les deux tâches le nombre de fois de la modification ceci s’applique à tous les devs du même projet. S’il trouve une erreur au niveau du code et bien il va la signaler à toute l’équipe.
DISTRIBUTION CONTINUE

Comme on dit “time is money”, maintenant que nous avons vérifié notre code via l’approche CI, comment la mettre le plus vite possible en production. Mais avant de parler de la production, il existe une autre approche qui est très importante et qui permet de nous faire gagner beaucoup de temps, car chaque entreprise cherche a protéger son portefeuille clients et pour y arriver il faut parfois délivrer le plus vite possible. Cette approche est basée sur la méthode Agile, elle s’appelle Distribution Continue.
On ne peut pas prendre l’application et la mettre en production directement, on doit faire des tests pour être sûr que l’application ne va pas tomber en panne une fois délivrée au client, Pour cela il faut déployer un environnement de test. La majorité des ESN utilisent deux environnement, QA Quality Assurance environment et UAT User Acceptance Test environment.
Grossièrement, la Distribution Continue permet de disposer d’une base de code toujours prête à être déployée dans un environnement de production.
Simulation
Une fois que le IC et le DC sont exploités, le chemin de l’unité déployable est appelé pipeline, une telle procédure est déclenchée lorsque le code est validé. Comme titre d’exemple d’IC, on trouve l’outil Jenkins son rôle sera de tester l’application avec toute ses modifications ainsi identifier les régressions le plus tôt possible . Dans cette partie de la simulation nous allons se contenter de voir un exemple de création de notre propre pipeline via OpenShift.
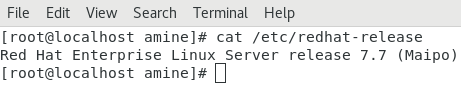
Tout d’abord, on va présenter notre espace de travail, on a décidé de travailler avec le SE RedHat 7.7
Il faut créer un compte sur le site de RedHat – OpenShift, il suffit de taper la commande :
[root@localhost amine]# subscription-manager list
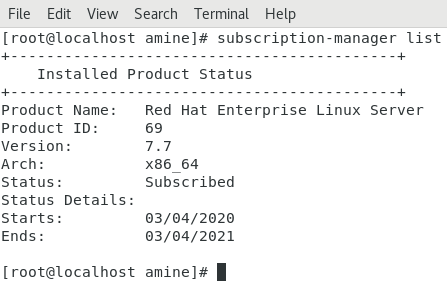
Comme vous pouvez le constater, on est inscrit pour une période d’un an afin d’exploiter le serveur, ensuite il faut récupérer son Pool ID, c’est votre identifiant au niveau du serveur afin que vous puissiez créer vos propres projet. Pour cela il suffit de taper la commande suivante :
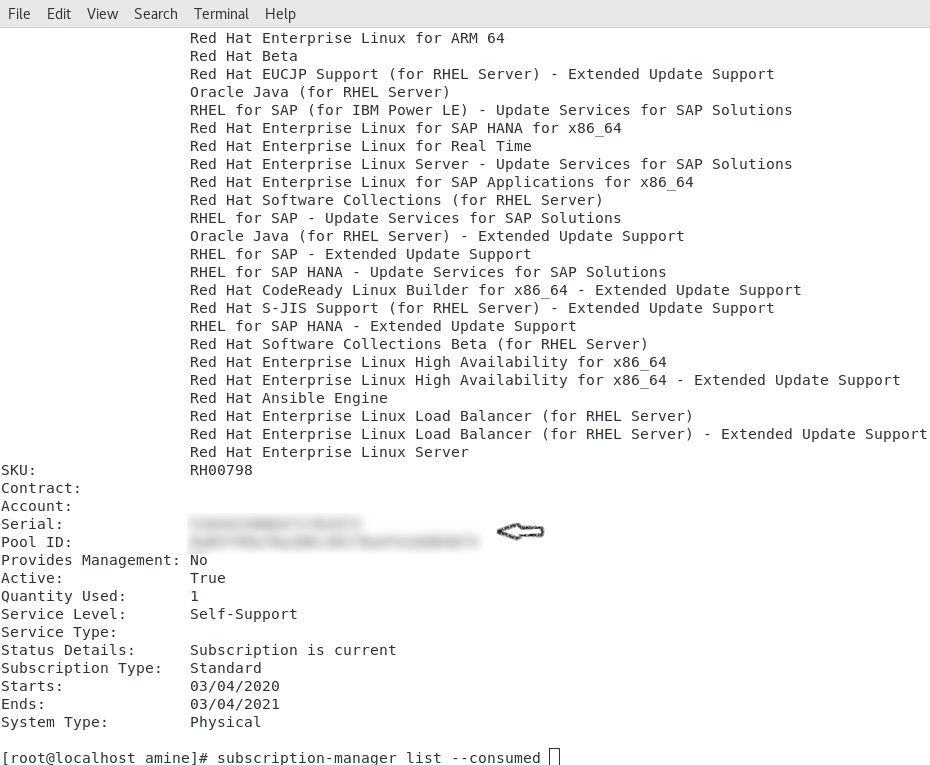
[root@localhost amine]# subscription-manager list --consumed
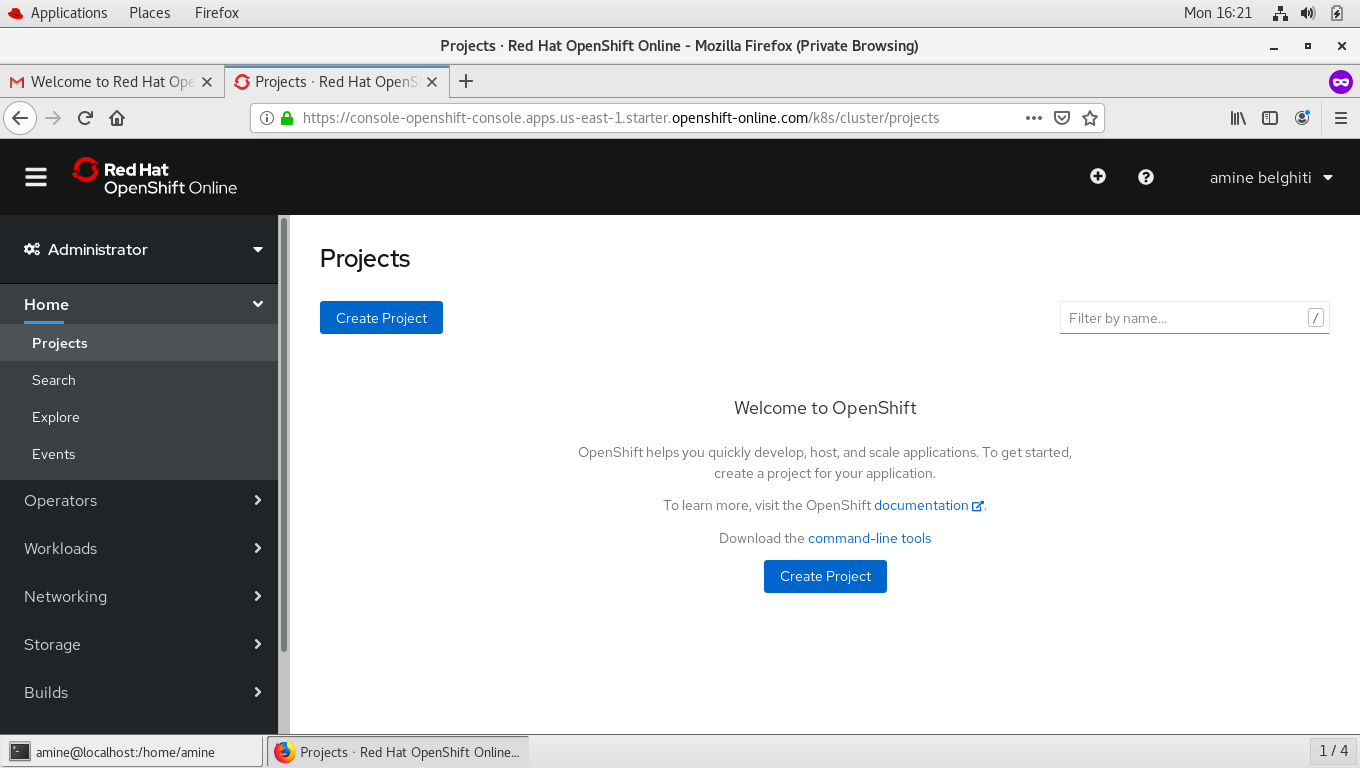
Commençons par la création de notre premier projet, qu’on va intituler CICD
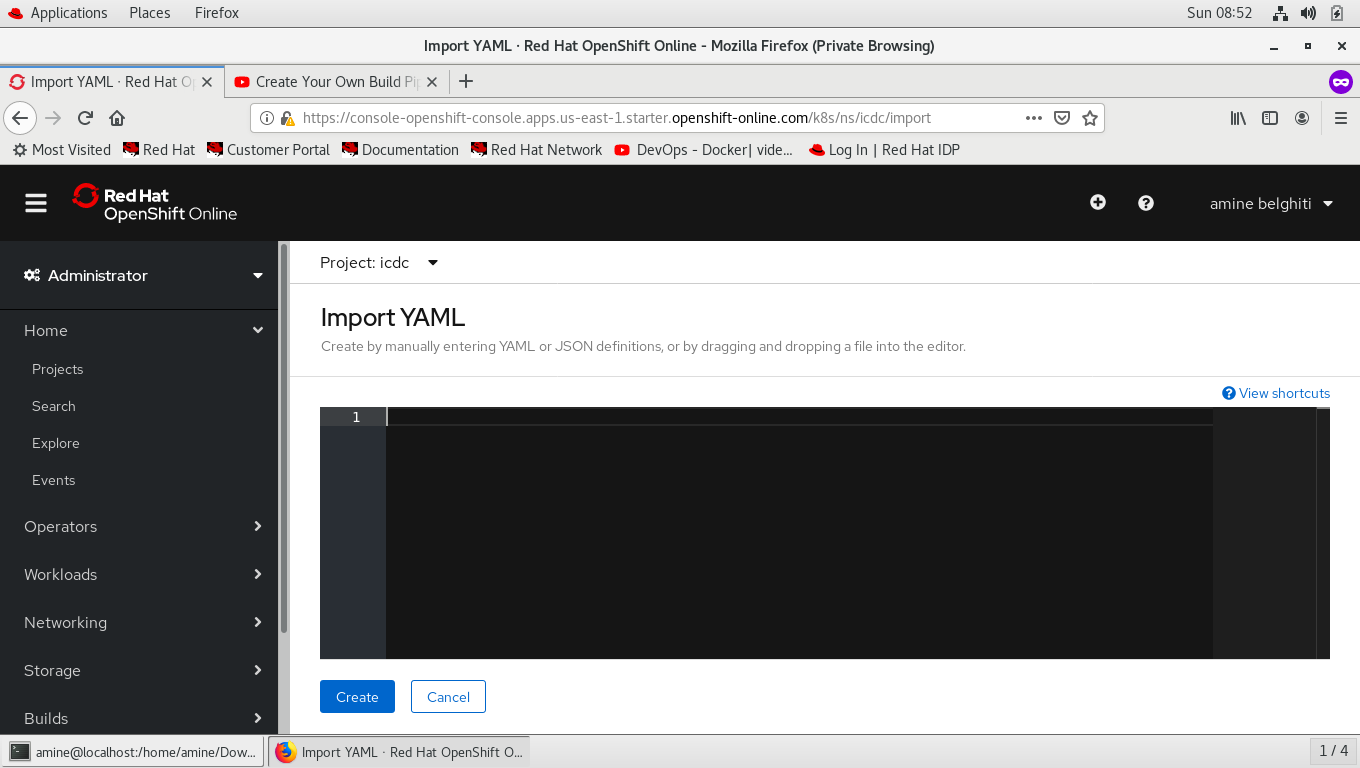
Copier ce fichier en-dessous dans yaml, c’est un fichier que nous avons téléchargé depuis Github afin de réaliser la simulation, le nom du projet est myfirstpipeline.
apiVersion: build.openshift.io/v1
kind: BuildConfig
metadata:
name: myfirstpipeline
labels:
name: myfirstpipeline
annotations:
pipeline.alpha.openshift.io/uses: '[{"name": "myphp", "namespace": "", "kind": "DeploymentConfig"}]'
spec:
triggers:
-
type: GitHub
github:
secret: secret101
-
type: Generic
generic:
secret: secret101
runPolicy: Serial
source:
type: None
strategy:
type: JenkinsPipeline
jenkinsPipelineStrategy:
jenkinsfile: "node() {\nstage 'build'\nopenshiftBuild(buildConfig: 'myphp', showBuildLogs: 'true')\nstage 'deploy'\nopenshiftDeploy(deploymentConfig: 'myphp')\nopenshiftScale(deploymentConfig: 'myphp',replicaCount: '2')\n}"
output:
resources:
postCommit:
Dans le champs Strategie on remarque que cette “pipeline” a comme type Jenkins.
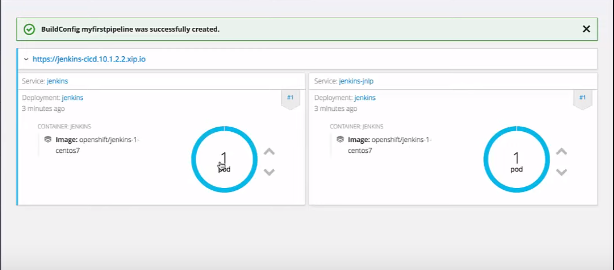
Une fois que notre pipeline est créé, il faut patienter le temps que notre POD Jenkins redémarre, on clique sur pod.
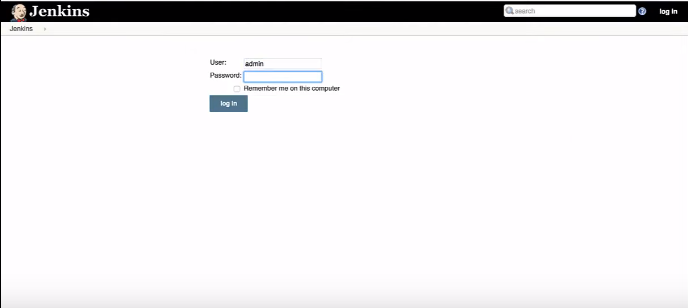
Dans le champ environnement, on copie le mot de passe qui va nous permettre de se connecter à Jenkins.
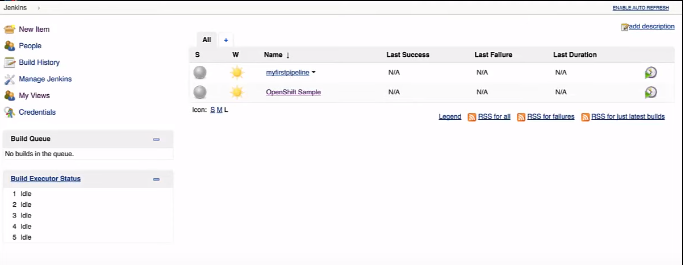
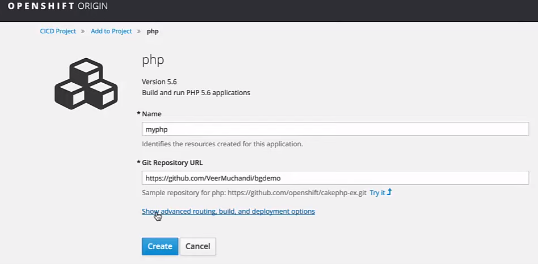
La configuration de Jenkins est faite, nous allons créer un autre projet en php que nous avons téléchargé depuis Github, on va nommé “myphp”.
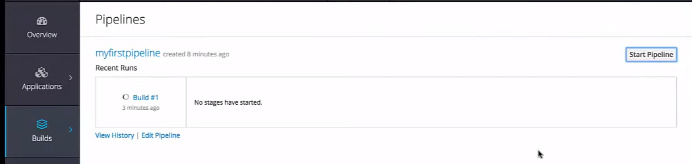
on va démarrer notre pipeline, sur le builds on choisie pipelines et apres on clique sur “start pipeline”.
REFERENCES
- https://www.youtube.com/watch?v=KTN_QBuDplo
- https://www.youtube.com/watch?v=uyiDNcSmwFw
- https://www.openshift.com/
- https://jenkins.io/
- https://github.com/KevinDick/myfirstpipeline/
- https://github.com/samuelDev/PHP-Projects
- https://www.youtube.com/watch?v=Cq1sR005B2E
- les images : https://www.google.fr/imghp?hl=fr&tab=wi&ogbl
